

随着AI技术的快速发展,很多视频基础模型已经能够生成画面精美、风格多样的短片,但一个根本性问题始终未被解决:尽管模型擅长生成看起来逼真的画面,却并没有真正理解三维世界。当镜头旋转、推进或环绕时,这些模型生成的视频中的建筑会扭曲变形,物体会凭空消失,空间比例也常常前后矛盾。换句话说,这些模型学会了二维像素的统计规律,却尚未建立稳定的三维空间认知。
为了解决这一问题,微软亚洲研究院推出了一种通过强化学习(RL)将视频生成与 3D 几何约束对齐的全新框架 World-R1。与此前需要修改架构或引入 3D 模块的方法不同,World-R1 无需改动模型结构、不依赖 3D 数据集、也不会增加推理开销,即可显著提升视频的几何一致性。相关论文已被 ICML 2026 接收。

该研究工作上线后迅速引发关注,短短几天内 GitHub 已获得 300多星,也从侧面印证了业界对“几何一致视频生成”这一方向的重视。
World-R1 演示视频(视频中的背景画面均由World-R1生成)
相关论文已整理于文末,欢迎点击相关链接,了解更多技术详情。
从“会生成”到“会理解”:World-R1 在做什么?
World-R1 的核心思路是:当前的视频基础模型内部已经编码了丰富的三维几何信息,而这些空间知识尚未被有效激活,需要一个足够有效的训练信号,去“唤醒”它。
对此,研究员们发现,强化学习可以把视频模型从“画面生成器”训练成“世界模拟器”。整个框架并不改动原始视频模型,而是在后训练阶段引入一套围绕三维一致性设计的强化学习机制,让模型在生成过程中逐步学会更稳定的空间结构、更可信的相机运动,以及更符合物理直觉的世界表现。
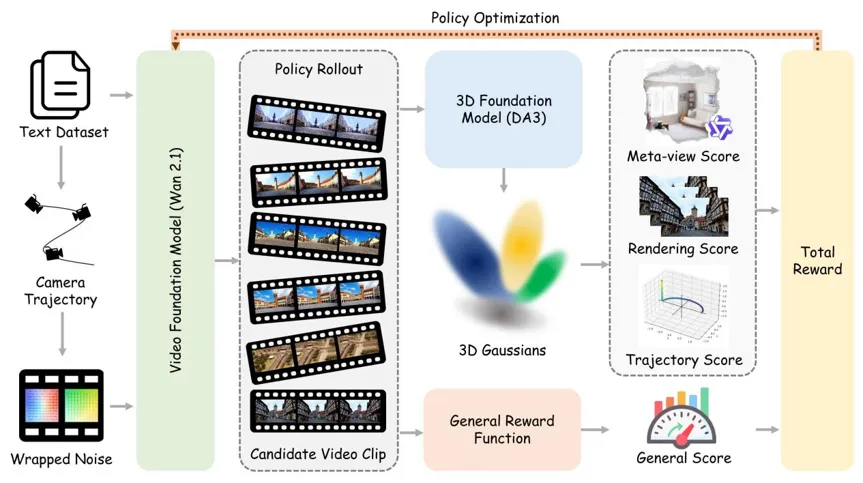
隐式相机控制:把运动先验”藏进”噪声里
在视频生成中,相机控制也一直是个难点。现有方法通常需要训练额外的控制网络来编码相机位姿。而World-R1 另辟蹊径,借鉴 Go-with-the-Flow 的思路,将相机运动轨迹通过光流投影和离散噪声传输,直接嵌入扩散模型的初始噪声中。
具体而言,系统首先从文本提示中检测运动关键词(如 “push in(镜头推进)””orbit left(左环绕)”),生成确定性的相机外参序列,然后通过针孔相机模型将 3D 轨迹投影为 2D 光流场,再利用离散噪声传输机制将运动结构注入初始噪声,同时保持标准正态分布。
最终效果是:模型无需改动架构,就能“天然”获得相机运动感知;同时推理流程保持不变,不增加额外成本。
用“奖励”教模型识别什么才是真正的三维世界
要让 RL 起作用,关键在于设计好奖励函数。World-R1 构建了一套精巧的复合奖励机制。给定一段生成的视频,系统首先利用 Depth Anything 3 将其”抬升”为 3D 高斯溅射(3DGS)表示,然后从四个维度评估质量:
- 元视角评分(S_meta):从一个大幅偏移的观察角度渲染 3D 重建结果,使用多模态大语言模型作为语义评判员,检测那些”正面看没问题但换个角度就穿帮”的几何幻觉。
- 重建保真度(S_recon):通过 1−LPIPS 度量 3D 重建结果与原视频的像素级一致性。
- 轨迹对齐度(S_traj):计算估计轨迹与目标轨迹的偏差,确保生成的相机运动严格遵循文字指令。
- 通用生成质量(R_gen):使用 HPSv3 对视频帧进行人类偏好评分,保持视觉美学和画质。
整套奖励利用 Flow-GRPO 框架优化,有效将视频生成器转化为几何一致的世界模拟器。

周期性解耦训练:刚性与动态的平衡术
过度强调 3D 一致性,会不可避免地抑制动态物体(如行走的行人、飘动的旗帜)的生成能力,让视频看起来十分“僵硬”。
为此,World-R1 采用了周期性解耦训练策略。在主训练阶段,模型使用完整奖励强化几何一致性,每隔 100 步切换到动态微调阶段,仅在包含约 500 条高动态场景描述的数据子集上使用通用奖励进行优化。
这一设计让模型可以在几何保真与动态生成之间取得平衡,有效防止过拟合于静态刚性约束。
只用 3000 条文本,也能学会世界规律
World-R1 的另一个亮点在于,它并不依赖昂贵的3D 资产或带标注的视频数据。研究员们利用 AI 生成了约 3000 条高质量纯文本场景描述,涵盖自然风景、城市建筑、超现实空间等多种视觉域,并按相机运动复杂度分级,包括隐式运动、单方向、复合轨迹等。这使模型在摆脱特定视觉分布偏见的同时,也学习了通用的物理几何规律。
实验结果:几何更稳定,画质也更好
研究员们基于开源视频生成基座分别训练了 1.3B的World-R1-Small(48 x H200 GPU)和 14B的World-R1-Large(96 x H200 GPU)两个版本,并进行了全面评估。
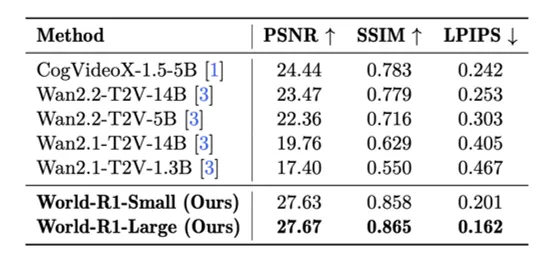
在 3D 重建评估中,World-R1-Small 对比基线 Wan 2.1-1.3B,PSNR 提升 +10.23 dB;World-R1-Large 对比 Wan 2.1-14B,提升 +7.91 dB。LPIPS 从 0.467 降至 0.201,几何幻觉被大幅抑制。
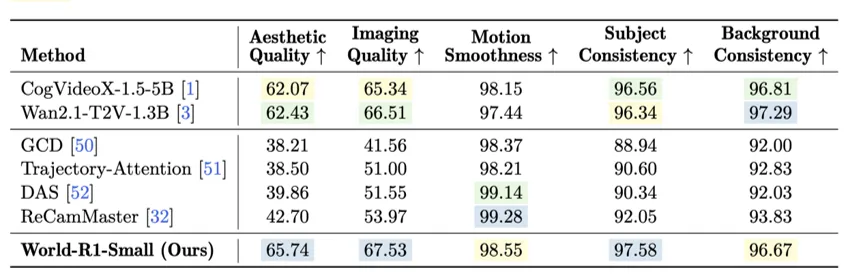
在 VBench 基准上,World-R1-Small 的美学质量(65.74)、成像质量(67.53)、主体一致性(97.58)均超越基线 Wan 2.1-1.3B,同时远超 ReCamMaster、DAS 等辅助控制方法(其美学质量仅 38~42 分)。这意味着,3D 能力的增强没有以牺牲画质为代价。
在涉及复杂相机运动(如围绕建筑旋转、沿走廊推进)的场景中,基线模型经常出现物体消失、墙壁扭曲等不真实过渡。而World-R1 则保持了严格的物体永久性和刚性几何。3DGS 重建可视化进一步验证了这一结论,World-R1 生成视频的点云致密且结构化,而基线模型的重建结果稀疏且噪声严重。

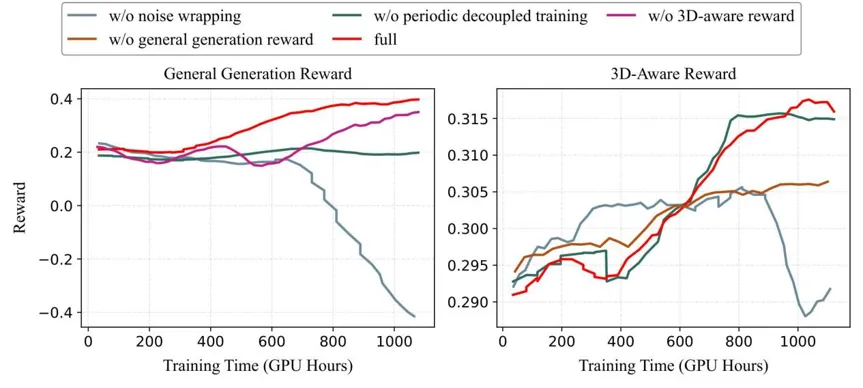
消融实验验证了各组件的贡献:
- 去除 3D 感知奖励:几何一致性显著下降,模型退化为普通视频生成器。
- 去除通用生成奖励:画面美学质量明显劣化,出现视觉退化。
- 去除隐式噪声注入:收敛速度大幅变慢,轨迹对齐精度下降。
- 去除周期性解耦训练:模型过拟合于静态刚性,动态场景生成能力丧失。
视频模型不必“重做”,也能学会三维世界
World-R1 提出了一种非常值得关注的全新路径:通过强化学习将视频生成模型与 3D 基础模型对齐,无需架构改动、无需 3D 数据、无需额外推理开销,即可将视频生成器升级为几何一致的世界模拟器。
这项工作证明了一个重要观点:让视频模型”理解”三维世界,不必推倒重来,只需用正确的奖励信号,唤醒它已有的空间感知即可。
未来,更高效的视频 RL 微调范式将成为关键方向,推动视频生成走向真正可交互、可推演、可用于具身智能训练和沉浸式内容创作等方向的世界模拟器。
World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
论文链接:https://arxiv.org/abs/2604.24764 (opens in new tab)
项目主页:http://aka.ms/world-r1 (opens in new tab)
GitHub链接:https://github.com/microsoft/World-R1 (opens in new tab)