

在大语言模型 (LLMs) 的训练中,数据的高效利用是决定模型最终能力的关键。过去的很多研究将精力集中在“数据筛选”(Data Selection)上,也就是如何从海量互联网语料中挑出最高质量的子集。
如今,这个问题依然十分重要。当前大模型通常只在海量数据上训练一轮或少数几轮,模型很可能只“读”一遍教材,因此数据样本呈现的时间顺序直接决定了模型的学习轨迹。如果把训练过程类比为上课,那么数据选择决定了教材内容,而数据组织则决定了课程表:先讲什么、什么时候复习、不同难度之间如何过渡,都会影响最终的学习效果。
基于此,微软亚洲研究院和南洋理工大学等研究团队联合发表了论文《Demystifying Data Organization for Enhanced LLM Training》,系统性地探索了数据组织对大模型训练的影响。研究员们巧妙地复用了数据筛选阶段预先计算好的样本级得分,在几乎不增加额外计算开销的前提下,提出了优化数据组织的四大核心法则,并据此设计了两种全新的数据排序策略 STR 和 SAW,实现了模型性能的显著跃升。相关论文已被 ACL 2026接收。
论文及代码链接已整理至文末,请点击查看。
数据组织为什么重要
过去的数据工作更多关注数据筛选:通过质量、难度、教育价值、可学习性等指标,为每个样本打分,再选择最有价值的子集。这些分数通常计算成本不低,但在很多流程中,它们只被用于一次筛选,之后训练样本仍然被随机打乱。
此次研究的核心观察是,这些已经计算出来的样本分数不应该只用于“选数据”,还可以继续用于“排数据”。在不改变数据内容、不增加模型规模、几乎不增加额外打分成本的前提下,合理的数据顺序就可能改善训练稳定性和最终性能。
从流程上看,研究员们将问题拆成了三个环节:Data Scoring (数据评分)为每个样本生成分数;Data Selection 可选地筛出子集;Data Organization (数据组织)则利用同一组分数重新排列训练样本。与数据选择改变数据规模不同,数据组织不改变样本数量,而是改变模型遇到样本的时间顺序。
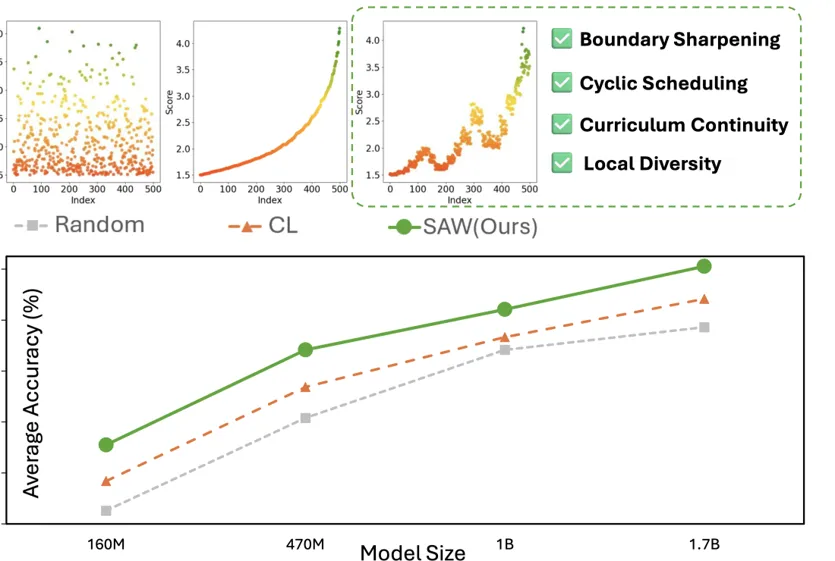
四条指南:给模型安排一张更好的课程表
本篇论文的价值不只在于提出 STR 和 SAW 两种排序方法,更在于系统总结了四条可迁移的数据组织指南。这些指南回答的是更基础的问题:如果已经有了样本分数,什么样的训练顺序更可能有效?
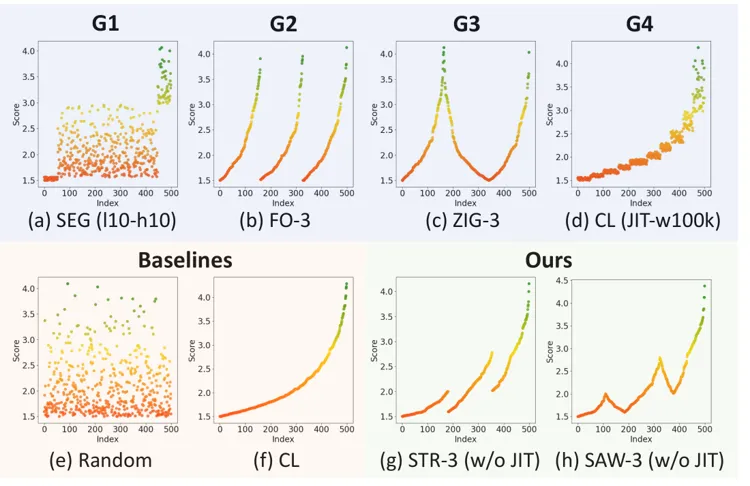
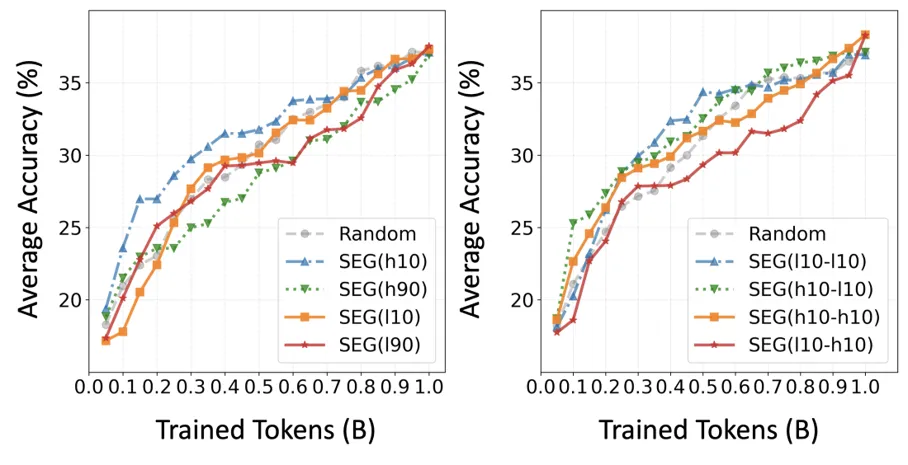
G1. 边界锐化:
Boundary Sharpening(边界锐化)强调训练初期和末期的数据分布。预训练阶段,实验显示结尾阶段接触高分样本特别重要,因为训练末端会更加直接地决定模型最终所能达到的能力上限。在 SFT 阶段,高分样本出现在开头和结尾都可能带来收益。开头帮助模型从预训练状态平稳过渡,结尾则进一步巩固最终能力。
论文用 Segment Ordering(SEG)验证了这一点。通过控制训练序列开头和结尾的样本分数区间,研究员们观察到以高分数据收尾的配置往往会带来更明显的性能提升。换句话说,模型最后看到什么,并不是无关紧要的细节。
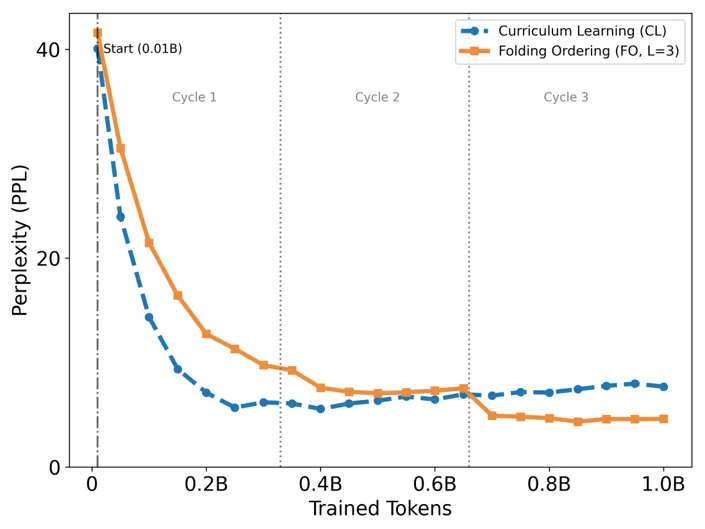
G2. 循环调度:
Cyclic Scheduling(循环调度)针对的是课程学习中常见的问题。直觉上,从简单到困难似乎合理,但在一轮训练中,如果模型很早学完基础样本,后面长时间只接触高分或高难样本,那么就可能遗忘早期知识。
为此,论文使用 Folding Ordering(FO)把排序后的数据折叠成多个循环,让模型在训练过程中周期性地重新接触不同分数区间的数据。这相当于在课程表里自然加入复习课,而不是等全部讲完才回头补基础。
实验数据显示,在难度最高的跨环境推理任务中,双模态融合方案的动作识别精度,较纯视觉基线模型提升3.3%;当视觉输入因遮挡失效时,脑电信号仍可稳定、精准解读人类真实意图。这表明,视觉与脑电的多模态融合效果优于传统单模态方案,展现出多模态脑机接口在复杂认知交互场景中的潜力。尤其在视觉信息匮乏、模糊的场景中,例如饮用动作、书写与绘画区分等,脑电信号能够提供关键补充信息,有效弥补视觉感知的短板。
G3. 课程连续性:
Curriculum Continuity(课程连续性)关注相邻训练阶段之间的平滑过渡。FO 能带来复习,但如果一个循环刚在高分样本中结束,下一个循环又突然跳回低分样本,那么优化器可能受到冲击,导致梯度剧烈波动。
论文提出 Zig-zag Ordering(ZIG),在相邻折叠层之间采用类似锯齿形的连接方式,让高低分变化更平滑。这保留了周期性复习的好处,同时减少了训练分布突变带来的不稳定。
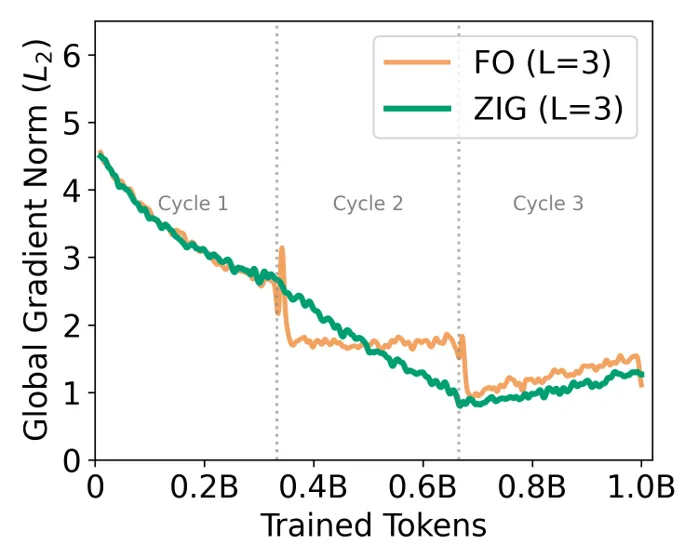
G4. 局部多样性:
Local Diversity(局部多样性)提醒大家,排序不能只看全局趋势。若样本严格按分数排列,那么相邻样本会高度相似,mini-batch 内的梯度多样性会下降,模型就更容易学习到局部重复模式。
论文用 Jittering Ordering(JIT)解决这一点。在保留全局顺序的同时,在局部窗口内进行随机打乱。这就像课程章节仍然按大纲推进,但每一小节里混合不同类型的练习题,从而增强泛化和鲁棒性。
STR 与 SAW:从原则到排序方法
基于上述指南,研究员们进一步提出两种跨指南的数据排序策略:Stair Ordering(STR)和 Saw Ordering(SAW)。它们并不是简单地把所有样本从低分排到高分,而是在整体进阶、阶段复习、平滑过渡和局部扰动之间做组合。
STR 结合 G1边界锐化、G2循环调度 和 G4局部多样性,保留整体课程推进的趋势,并在阶段转换区域引入 FO 式的折叠复习,再通过 JIT 保持局部多样性。因此,STR 更像一张阶梯式课程表:大方向不断向更高分样本推进,但在关键台阶处安排复习和混合练习。
SAW 在 STR 的基础上进一步加入 G3课程连续性,用 ZIG 替代转换区域中的折叠连接,使阶段之间过渡更连续。它的序列形态更像锯齿波,既能回看不同分数区间,又尽量避免突然从高分样本跳回低分样本。
实验结果:排序本身也能带来稳定收益
研究员们在通用预训练和 SFT 两类场景中验证了这些指南。预训练使用 FineWeb-Edu 和QuratedPajama等数据,SFT 则覆盖数学推理和代码生成任务,使用 DeepMath-103K 与 OpenCodeInstruct 等数据。
结果显示,STR 和 SAW 在 FineWeb-Edu 预训练平均准确率上都超过 Random。而且当规模继续放大时,排序策略的优势仍然存在。

除了下游任务平均准确率,研究员们还在 DCLM 测试损失上观察到一致收益。这说明数据组织不仅能提升 benchmark 表现,也会影响语言建模本身的训练质量。
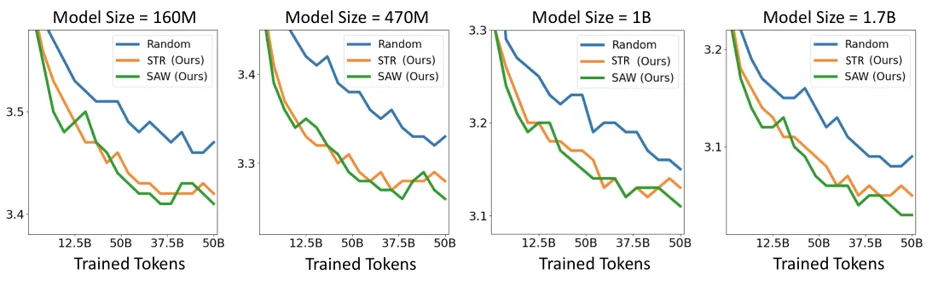
Data-centric AI 也需要关注数据的时间顺序
本论文研究表明,在大模型训练中,数据价值不只取决于样本是否被选中,也取决于样本何时、以怎样的节奏出现。当训练只进行一轮或少数几轮时,数据顺序会直接塑造模型的学习轨迹。
从实践角度看,这一方向的吸引力在于成本低、兼容性强:它可以复用数据效率流程中已经生成的样本分数,不需要改变模型架构,也不需要额外扩大数据规模。当然,排序效果仍然依赖于样本分数本身是否可靠,数据组织并不能替代高质量的数据评分和数据筛选。
但作为以数据为中心的AI(Data-centric AI)的一部分,数据组织提供了一个新的优化维度。如果说数据选择是在回答“模型应该学什么”,那么数据组织进一步回答的是“模型应该按什么顺序学”。对于越来越昂贵的大模型训练来说,这张课程表本身可能就是提升训练效能的一把新钥匙。
Demystifying Data Organization for Enhanced LLM Training
论文链接:https://arxiv.org/abs/2605.30334 (opens in new tab)
代码链接:https://github.com/microsoft/data-efficacy (opens in new tab)