

如今的大语言模型早已在数学领域展现出令人惊叹的实力,在 AIME 美国数学邀请赛、IMO 国际数学奥林匹克竞赛等高难度抽象数学竞赛中,多款主流模型都能交出近乎满分的答卷。这一表现也成为大模型推理能力持续突破的亮眼标签。
但是,这些在抽象数学题中所向披靡的“学霸”,面对藏在现实场景中的数学问题时却频频失手,抽象解题能力始终无法转化为可靠的现实应用能力,形成了巨大的性能落差。比如模型能精准解出抽象的数字三元组计算问题,可当这些数字对应成无人机飞行步数、智能能源系统的组件参数,仅为数学逻辑披上一层现实叙事的“马甲”后,其解题准确率便大幅下降。
针对这一问题,微软亚洲研究院联合香港中文大学等多所高校展开系统性探索,推出了 ContextMATH 情境化数学推理基准测试集,通过对 61 款主流大模型的全面测试,揭示了大模型在抽象与情境化数学推理之间的能力差距,为大模型的实际应用优化提供了关键科学依据。相关论文已被ICLR 2026接收。
From Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
论文链接:https://openreview.net/forum?id=KBknLdXxTa (opens in new tab)
大模型解不了场景化数学题的原因:读不懂题
为了精准找到大模型解不了场景数学题的核心症结,研究员们设计了ContextMATH 基准测试集,将 AIME 和 MATH-500 的抽象数学题目转化为两种贴合实际应用场景的题目,以探究模型在情境化场景挑战下的数学问题提炼和推理能力。
第一种是情境化重构(SG)。其主要思路是保持原题的数学难度和逻辑结构不变,但将所有抽象的数学元素,如变量、方程嵌入到一个真实可信的叙事场景中。例如,原本的方程 x+y=10 被改写为“油罐A中的原油量与油桶B中的原油量之和为10”。这种改写不增加任何新的数学推理步骤,仅仅是改变了问题的表述形式。其目的是测试模型是否能在无关的上下文细节干扰下,准确识别出背后的数学骨架。
第二种是复杂度扩展(CS)场景。这类题目会将原本直接给出的显性数学条件,隐藏为需要先推导的子问题,模拟现实中人们解决问题时需要先搜集信息、推导条件再解题的真实场景。例如,问题不会直接告诉模型“有25盏灯”,而是描述为“指示灯的唯一两两组合数恰好为 300”。模型必须先解决这个隐含的计数子问题,才能得到关键的“25”这个数字。这种设计迫使模型进行分层推理,更贴近工程师或分析师在现实中必须经历的信息提炼过程。

基于 ContextMATH 测试集,研究员们对61款具有代表性的开源及闭源大模型进行了评估,涵盖了从数十亿参数到万亿级参数的不同规模。结果显示,所有模型在情境化任务上的表现都出现了显著下滑。平均而言,开源模型在情境化重构任务上的准确率下降了13%,而在复杂性扩展任务上更是下降了34%。即便参数量达 1.8 万亿的 GPT-5,在 2025 年 AIME 的复杂性缩放题中,准确率也下滑了 26%。
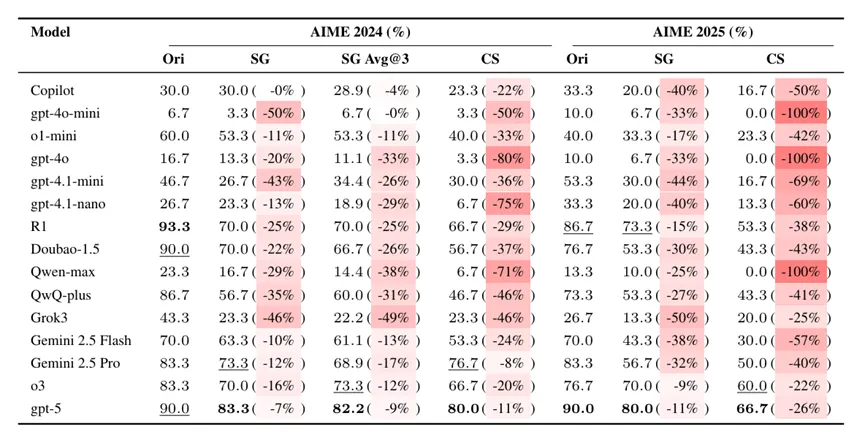
通过对所有失败案例的深度拆解分析,研究员们发现模型出现错误的原因有四种:提炼错误(从叙事到数学的映射错误)、计算错误、逻辑错误和其他错误(如截断、重复)。其中约80%的解题错误都源于“问题提炼出错”,也就是大模型无法从复杂的场景描述中,准确提取出背后的核心数学逻辑。比如将“齿轮的旋转周期可调节,但每分钟旋转次数不得超过 6 次”,对应不等式 x≥10(x 为每次旋转的秒数),从解题的第一步就偏离了正确方向。
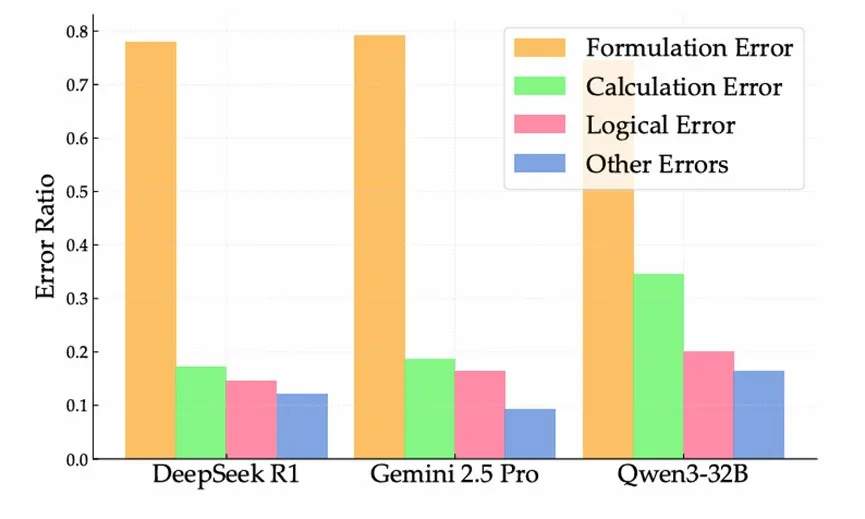
这场测试揭示了一个事实,即当前大语言模型在抽象数学推理与情境化数学推理之间,存在显著且难以消除的能力差距,抽象解题的高水准并不能转化为情境化解题的可靠性。
场景数学能力不能“分而治之”,要“融会贯通”
面对场景化的数学问题,大模型究竟是数学计算能力不足,还是对题目的理解能力存在短板?研究员们通过对模型错误类型的系统性拆解,给出了明确的答案:大模型并非不会计算,而是读不懂题。
针对这一问题,研究员们进一步指出当前大语言模型在解决情境化数学问题时,面临着两大能力瓶颈:
- 第一是公式化能力,也就是从场景化的叙述中,准确抽象出方程、变量、约束条件等核心数学要素的能力,这是解决情境化数学问题的前提;
- 第二是推理能力,也就是对已经成功抽象出的数学问题,进行正确求解的能力,这是完成解题的关键。
为了突破这两大能力瓶颈并寻找可行的解决方案,研究员们尝试了两种截然不同的训练策略。
第一种策略是“端到端的混合训练”。研究员们构建了一个包含抽象数学题与合成场景题的混合数据集,并对不同规模的基础模型进行了微调。结果显示:使用混合数据进行训练的模型,其在情境化问题上的表现获得了显著提升,同时其原有的抽象数学解题能力并未受损。这意味着模型确实可以通过接触大量情境化案例,来学习如何更好地完成从叙事到数学的转换。
然而,第二种策略的结果却发人深省。研究员们尝试训练了一个专门的公式化模型,其唯一任务就是将场景描述转化为对应的抽象数学问题,然后再交由一个独立的、能力很强的“求解器”模型去解答。令人意外的是,这种将任务拆解为“提炼”与“求解”两个孤立步骤的做法完全无效,甚至导致最终的整体性能相比直接求解时大幅下降。
两种训练策略的结果表明:大模型的场景数学推理能力是一种综合能力,无法拆解为孤立的技能进行培养,必须通过融合式训练,让模型同时提升公式化和推理能力。
大模型训练的下一站:从解题到理解世界
研究员们此次针对大模型情境化数学推理能力的研究,虽然以数学领域为核心的探索对象,但其得出的研究结论和创新的研究方法,为整个人工智能领域的发展提供了多维度的重要启示,同时也表明,未来模型能力的提升,不仅依赖于更大的规模和更强的计算能力,还取决于模型对现实世界的理解能力。
首先,对于AI模型的优化与训练,仅让模型在抽象数学题库上死刷题,是无法培养出应对现实复杂问题的能力。未来的模型训练要走“抽象+场景”的融合路线,只有将逻辑推导置于丰富多变的现实语境中,模型才能真正具备解决实际问题的能力。而这对于推动 AI 技术在教育辅导、金融量化、工程设计等依赖精密数学应用的领域真正落地,具有重要的指导意义。
此外,ContextMATH的构建思路具有高度的可迁移性。这种将标准化、高质量的抽象测试题,通过系统化方法转化为贴近现实的情境化任务的做法,可以被复制到代码生成、机器人规划、逻辑推理等多个AI能力评估领域。这为整个AI的研究提供了一种通用的、低成本、高效率的测试范式,用以更真实、更全面地衡量大语言模型在脱离实验环境后的真实智能水平。