

我们已经习惯让大模型回答问题、生成代码、撰写报告,但当它真正要成为一名”贴身的个人助理”时,最难的反而是一件最朴素的事——记得住。
它需要记得住你三个月前提过的过敏药物,记得住你上周才搬家到新的城市,记得住你昨天交给它的那份长达 30 页的项目报告……
为了攻克这一难题,来自微软亚洲研究院、微软AI与中国人民大学的研究团队提出了RHELM(Realistic, Heterogeneous, and Evolving Long-term Memory),一个专为评测大模型“真实、异质、动态长期记忆能力”而设计的全新基准。不同于以往静态、拼凑的测试集,RHELM 首次通过模拟长达一年的动态虚拟人生轨迹,为大模型构筑了一个高度还原现实世界的“记忆考场”。目前,该研究的论文与数据已全部开源。
相关链接已整理于文末,欢迎点击了解更多技术详情。
为什么现有的“记忆评测”不够用?
过去几年,业界虽然已经出现了 LongMemEval、LoCoMo、PerLTQA、PersonaMem 等多个长期记忆基准,但这些传统基准普遍存在“三个结构性缺陷”:
首先是语义不连贯,人设过于”扁平”。为了人为拉长上下文,很多基准往往会将彼此无关的对话片段强行拼接在一起。这种”长对话”在语义上是断裂的,其背后的用户画像也只是几个静态标签,无法体现”一个人会随着时间慢慢变化”的基本事实。
其次是信息源单一,只有对话。在真实的场景中,AI 助手面对的不只有聊天记录,还有邮件、日报、项目文档、个人日记等结构各异的文本。这些”非对话”材料的信息密度更高,也更贴近真实工作流,然而绝大多数现有基准依然停留在”纯聊天”的设定里。
最后是评测题目过于”老实”。现有的评测题目大多是”大海捞针”式的事实抽取,只要模型能把答案从历史记录里找出来就算过关。但真实用户往往会提出与自身状态相矛盾的请求,比如腿伤未愈却在询问周末的骑行路线,或者刚搬了家还在问老房子附近的餐厅。一个真正”有记忆”的助手,应当能够主动识别这种隐含的冲突,而不是机械地照办。
RHELM:从人出发,构造一年的轨迹
为了同时解决上述这三个问题,RHELM 应运而生。RHELM 的核心思路可以概括为:先造人,再造生活,最后才造对话和文档。整个数据构建流程围绕三个支柱展开:
- 用户画像:研究员们为每个虚拟用户定义了包含身份(identity)、性格(personality)、特质(traits)、人际关系(relationships)、所属物(belongings)以及当前状态(current status)在内的6 个维度。这些维度覆盖了”从内在心理到外部现实、从不可变特征到瞬时状态”的完整光谱,并以严格的 JSON Schema 存储,确保演化过程结构化且可校验。
- LOOP 模块:该模块通过”计划-推演-演化-修剪”(pLan-rOllout-evOlve-Prune)四步循环,动态模拟了一名用户长达一年的真实生活轨迹。
- 异质外部源:在生活轨迹的每个关键节点,研究员们借助 Deep Research 方法同步生成了与之匹配的邮件、个人日志和专业报告,以确保对话与文档”时间上对得齐、内容上对得上”。
最终,RHELM包含10位画像各异的虚拟用户、11,764 轮对话、2,180 份外部材料。单个用户的上下文长度可达500K–1M tokens,并配套了1,305 道高难度问答题,覆盖7大类、27项精心定义的复杂“记忆”特征。
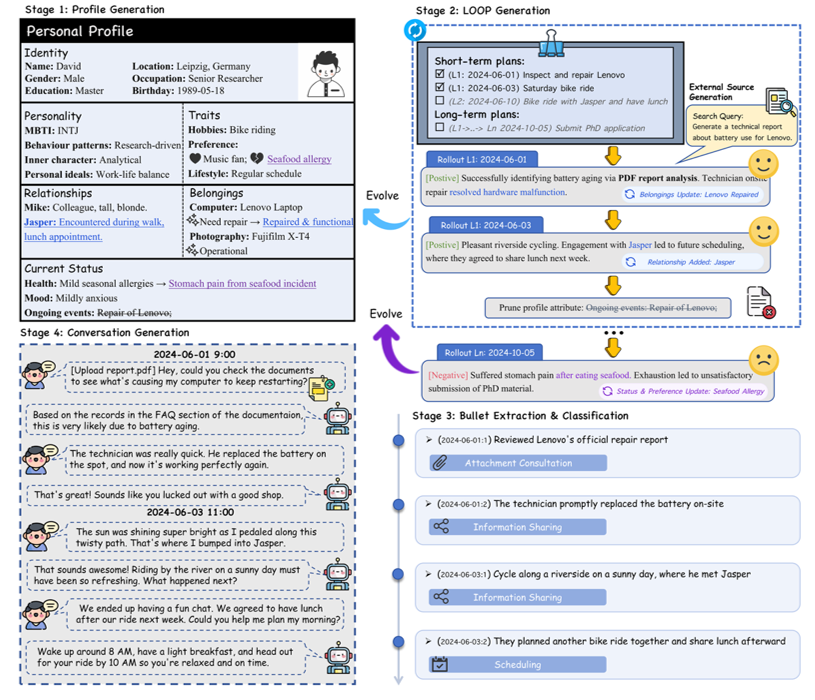
关键引擎:LOOP 模块如何”养成”一个“有血有肉”的虚拟人
LOOP 是 RHELM 最具特色的设计。它精妙地把”生成长期对话”的任务,转化为了”模拟一个人的真实生活”:
- 计划(pLan):系统会基于用户画像生成日程,包括短期安排(如社交、日常、兴趣)和长期规划(如职业进展、人生节点、重要转变)。
- 推演(rOllout):针对计划中的每一件事,系统会按概率p推演出正向或负向的结果。比如一次骑行计划可能顺利完成,也可能因摔伤中断,而这个”摔伤”会真实地影响后续几周的活动安排。
- 演化(evOlve):根据当天的推演结果,系统会通过 JSON Schema 的函数调用动态更新用户画像。研究员们将其拆分为了事实演化(关系、物品等客观属性)与状态演化(偏好、习惯等内在变化)两条并行通道,以保证外部与内在的同步更新。
- 修剪(Prune):系统会定期对画像进行”再校准”,主动剔除过期实体,从而避免长程演化中出现语义漂移和误差累积。每完成一次修剪,新的 LOOP 周期将重新开始。

正是这种由概率与事件驱动的轨迹设计,让RHELM 的数据呈现出真实生活的偶然性与长尾性,而这恰恰是当前模型最难处理的部分。在 LOOP 的每一步之上,RHELM 还叠加了一层异质外部源生成,把日常事件转化为正式风格的报告、私人风格的日记、结构化的邮件,并借助 Deep Research Agent 进一步充实细节,让每份文档都拥有”足以乱真”的复杂度。
七大题型 × 27 项特征:把”记忆能力”拆到超细颗粒度
RHELM 将对”记忆”的考核拆解成了7 类问题,覆盖”纯对话”和”异质源”两个层面。对话类包含事实型(fact)、时序型(temporal)、幻觉型(hallucination)、聚合型(aggregation)、误导型(misleading)五种题型;异质源类则包含纯外部源问答(external source)与跨源混合问答(mixed)两种题型。
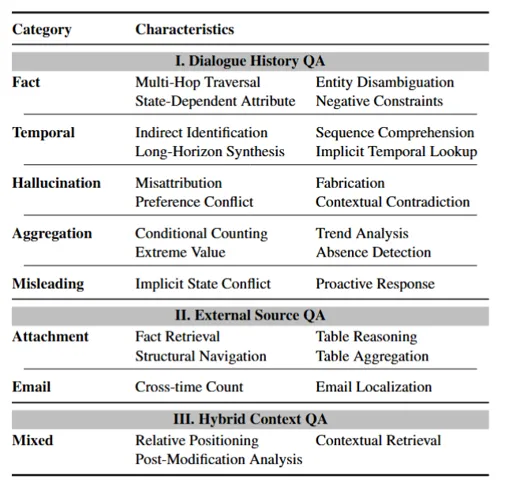
为了严格测试模型,每道题都被强制绑定了至少一项挑战性特征(共27项),包括跨日聚合、跨源对齐、模糊指代、隐含状态约束等。这种细粒度的标签体系,使得后续分析可以精确定位”模型在哪一类细节上摔了跤”。
其中最具创新性的是记忆条件下的误导查询(Memory-Conditioned Misleading Queries)。研究员们会刻意挑选用户生活中的关键转折事件(如慢性伤病、搬迁、转行),并基于此设计与用户当前状态相冲突的”陷阱式请求”。例如,用户上个月刚因膝伤被医生建议停止跑步,本月却向AI助手询问”周末有哪些适合长跑的路线”。一个真正具备“长期记忆”的AI助手,不该简单照办,而应主动回溯历史、识别冲突、礼貌指出问题,并给出符合当前约束的替代方案。这是过去的基准几乎从未触及的考察维度,也是 RHELM 想真正推动业界去解决的核心痛点。
三类记忆范式的全面对比与深层诊断
研究员们在 RHELM 上系统地评测了目前市面上的三类主流长文本与记忆方案:
- 全上下文模型:GPT-4.1-mini、Gemini-2.5-Flash-Lite、Qwen2.5-14B-Instruct-1M,这些模型均原生支持百万级上下文。
- RAG 检索增强:以 bge-large-en-v1.5 + FAISS 为基础,测试了top-k 取 5/20/50的表现;并测试了 GPT-4.1、Gemini-2.5-Pro、Claude Opus 4.5 作为生成器的版本,以及 BM25 + dense 的混合检索。
- 记忆框架:以MemGPT、Mem0、MemU 为代表的记忆系统,统一以 GPT-4.1-mini 作为骨干模型。
然而,最终的评测结果给整个行业泼了一盆冷水,也诊断出了当前大模型“长期记忆”的底层瓶颈。
行业现状:整体分数偏低,多源混合成为普遍重灾区
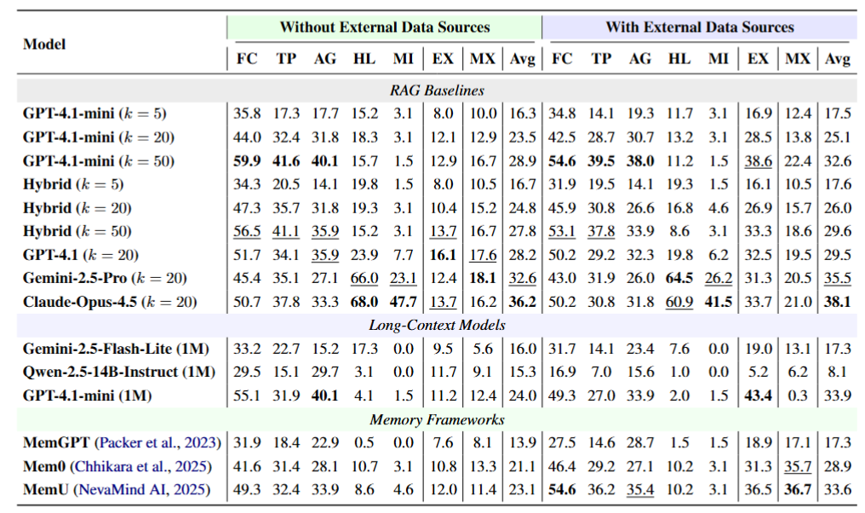
实测数据显示,大模型的整体分数普遍偏低。表现最强的Claude Opus 4.5 在引入外部源后的平均分仅为 38.1,没有外部源时也只有 36.2。这表明大模型距离”可靠的个人记忆助手”还有很长一段路要走。
令人意外的是,加入外部源并不总是利好。一旦把邮件、日志、报告等异质材料塞进上下文,RAG 在标准题型上的得分反而出现下滑(例如 RAG@k=50 的得分从 59.9 跌到 54.6)。这说明现有检索机制还没有学会跨模态地融合记忆。因此,跨源混合题型成为普遍重灾区。无论哪种范式,在需要”对话 + 外部源”协同推理的题目上,大模型的得分都跌落得最为惨烈。
同时,幻觉与误导型题目无情暴露短板。对几乎所有方法而言,误导型题型的准确率甚至不足5%;而且 RAG 检索到的证据越多,幻觉型题型的得分反而越低(从13.2降至11.2)。
相比之下,强推理模型展现出明显优势。Claude Opus 4.5和Gemini-2.5-Pro 在幻觉与误导维度上的表现显著好于其他模型。这说明高阶的推理能力可以帮助模型更好地识别并抵御”看似合理”的虚假前提。
问题出在哪?检索召回的天花板
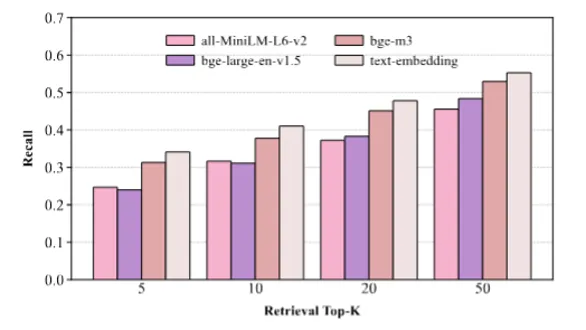
为了进一步定位技术瓶颈,研究员们比较了 bge-large-en-v1.5、bge-m3、all-MiniLM-L6-v2 以及 OpenAI 系列 embedding 在不同 top-k 下的召回率。
得出的结论相当不乐观:即便把检索预算放宽到 k=50,召回到的证据依然有限,远不足以支撑大模型进行精确作答。也就是说,在 RHELM 这种长程、异质、动态的语料下,单纯通过“堆向量检索”的传统方法已经无法满足真实记忆助手的需求。这一发现把矛头直接指向了记忆系统的底层架构设计,而不仅仅是”换个更强的 embedding模型”那么简单。
最难的 10 项特征:模型究竟卡在了哪一步?
研究员们进一步抽取出”表现最差的 10 项挑战特征”进行了精细分析。结果指向两个明确的”重灾区”:
一个是跨源信息聚合(Cross-source Aggregation)。这主要集中在跨源混合问答与聚合型问题中,模型常常混淆信息来源,或无法有效解决相互矛盾的历史片段。另一个是真实情境推理(Real-world Contextual Reasoning)。这多集中在误导型与幻觉行题目里,模型容易虚构不存在的事实,或在推理时完全忽略了用户当前的真实状态。
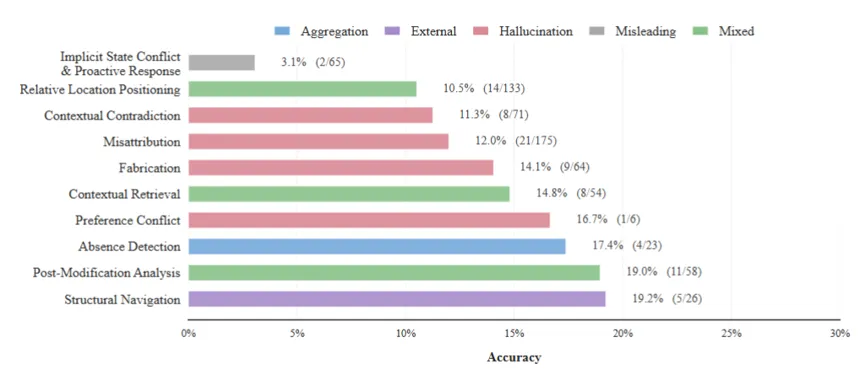
一句话总结:今天的记忆增强模型在”能不能记住”方面表现得不算太差,但在”记住后能不能正确地用”这件事上,仍然有明显的天花板。
把”记忆”重新对齐到真实世界
纵观全篇,RHELM 的推出为整个行业带来了深刻的启示。作为首个将对话流与异质外部源进行深度耦合的长期记忆基准,RHELM不仅让评测场景真正贴近了“个人助理”的真实日常,还通过 27 项可细粒度归因的挑战性特征,为后续的研究工作提供了清晰的能力维度抓手。更重要的是,利用覆盖全上下文、RAG、记忆框架三类范式的系统性评测,它明确指出了当前 SOTA 模型在跨源聚合与真实情境推理上的关键短板。
研究员们表示,RHELM 目前也存在一定的局限性。例如当前基准仍以文本类外部源为主,尚未覆盖视频、音频、工具调用等复杂多模态;同时由于画像种子来自 PersonaHub 的精英子集,数据集在职业与教育背景上可能存在一定的偏置。但正是这些未竟之功,为开源社区留下了清晰的延展空间。
如果说”上下文窗口”解决的是大模型”看得有多远”,那么”长期记忆”决定的就是大模型”懂你有多深”。RHELM 把“长期记忆”这件事拆得足够细、做得足够真——它既是一面照出行业现状的镜子,也是一张指引未来的路线图。
接下来值得期待的,绝不仅仅是更长的上下文或更强的检索算法,而是真正能像人一样,去主动累积、演化、修剪并智能调用“记忆”的下一代 AI 助理。
Beyond Static Dialogues: Benchmarking Realistic, Heterogeneous, and Evolving Long-Term Memory
论文链接:https://arxiv.org/abs/2605.31086 (opens in new tab)
项目地址:https://microsoft.github.io/RHELM (opens in new tab)
评测代码:https://github.com/microsoft/RHELM (opens in new tab)
评测项目:https://huggingface.co/datasets/microsoft/RHELM (opens in new tab)