

如果让今天最强的大模型去参加一场国家计算机等级考试(NCRE),它能拿多少分?
近期,微软亚洲研究院的研究员们把 NCRE 一、二级的 200 道 Word、Excel、PPT 实操题搬到 AI 面前,让 7 个前沿大模型作答,并用官方评分引擎逐条打分。然而,测试结果却与我们的直觉大相径庭:在普通考生普遍能拿满分的考试中,最强单轮模型只考了 36.6 分;即便是配上了能反复执行调试的“编程智能体”,最高也只有 68.8 分。作为对比,社区贡献的标准解答平均能拿到 95.5 分。
这一戏剧性的翻车现场,并非大模型们的偶尔失手,而是一场硬核学术测试带来的真实一幕。这项研究来自微软亚洲研究院的最新成果《Mind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?》。研究员们希望借此探寻,AI 浪潮背后,大模型距离真正精通日常办公究竟还有多远?
论文信息已整理于文末,欢迎点击相关链接,了解更多技术详情。
用 NCRE 国家级考试来“卷”AI
作为知识工作者的基础工具,Microsoft Office 的全球用户已超十亿。在日常办公中,一份合格的文档往往需要数十步精确的操作:页边距调整、样式设置、图表生成、动画效果、水印添加……任何一步出错,都可能导致整页排版走样。
然而,在现有的主流大模型基准测试中,Office 办公能力长期被掩盖。这些测试要么只覆盖单一应用,要么用合成任务凑数,甚至直接请另一个大模型来充当评委。为了打破这种局限,研究员们希望引入一场真正的考试和一套真实的评分标准,以此来精准量化 AI 与真人在办公自动化领域的实际差距。
于是,研究员们把目光投向了教育部考试中心组织的标准化考试NCRE(全国计算机等级考试)一、二级 Office 模块。该考试每年报考人数以百万计,广泛应用于就业、公务员招考、考研与职称评定。引入 NCRE 作为测试基准有三大独特优势:题目由专家命制,难度经过严格校准;评分细则机器可读,保证了绝对的客观性;最重要的是,它的尺度与真人完全一致——AI 最终的得分,就是它在官方满分中实打实拿到的分数。
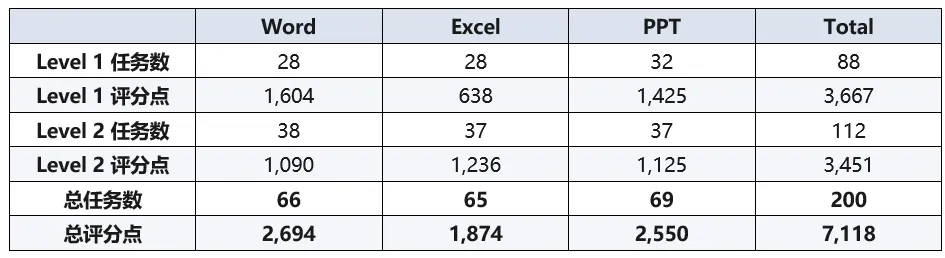
基于这套严苛的标准,研究员们整理出了 200 道极具代表性的题目,其中一级 88 道、二级 112 道,全面覆盖三大核心应用。这些题目被拆解为了 7,118 条可由机器判定的细粒度评分点。这套专为大模型打造的全新办公自动化基准测试,被命名为 OfficeEval。

裸考 vs 开机考:七大前沿大模型真实能力起底
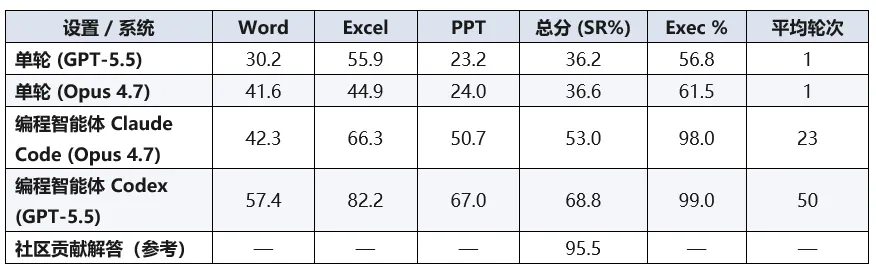
为了全面评估 AI 的真实潜力,研究员们设计了两种作答范式。第一种是“单轮代码生成”模式:模型一次性接收任务说明、截图与文件路径,随后直接输出 Python 代码,代码运行完即刻提交,期间没有任何报错反馈,也完全无法重试。
第二种是“编程智能体”模式,以评测更接近人类的实际办公状态:由 Claude Opus 4.7 驱动的 Claude Code 以及由 GPT-5.5 驱动的 Codex可以反复编写代码、运行程序、查看报错、再进行修复。每道题的作答上限长达一小时,且允许它们自由调用 Windows COM 等Office中的技术。
在这场包含“裸考”与“开机考”的双重试炼中,研究员们评测了七个前沿大模型,其中包括闭源的 Claude Opus 4.7、GPT-5.5、Gemini 3.1 Pro,以及开源的 Kimi-K2.6、Qwen3.5-397B-A17B、MiMo-V2.5、Grok-4.1-fast。
在单轮设置下,各模型的表现普遍低迷。Claude Opus 4.7 以 36.6% 的得分率位居榜首,GPT-5.5 以 36.2% 紧随其后,而 Gemini 3.1 Pro 仅获得 16.3% 的分数。在开源阵营中,除 Kimi-K2.6 拿到了接近双位数的成绩外,其余模型均在个位数徘徊。顶尖模型生成的程序也只有约六成能够勉强执行。
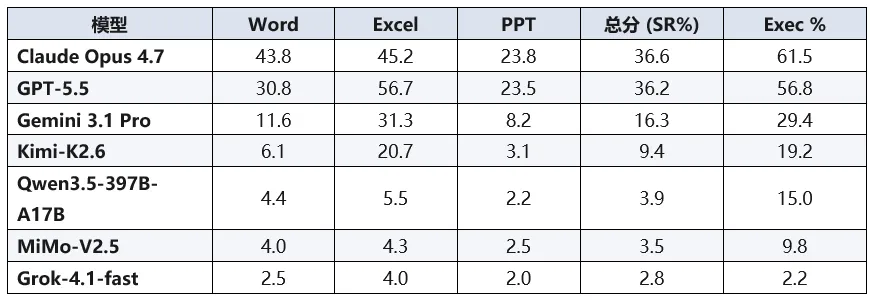
当场景切换到允许反复试错的编程智能体模式时,情况有了显著改善。得益于多次迭代与调用 COM 自动化的能力,Codex 的总分为68.8%,比其单轮表现提升了 32.6 个百分点;Claude Code 的得分率也提高到了 53.0%。在多次纠错后,两者的代码执行成功率均达到了 98%–99% 的水准。但即使有智能体形态的外挂加持,AI 的最高成绩也未能触及及格线(70%),距离人类社区贡献的标准答案(95.5%)仍有超过 25 个百分点的差距。这表明,仅赋予大模型“重试”的机会,依然无法从根本上解决它们在复杂办公场景下的无力感。
AI 究竟被哪块“硬骨头”卡住了?
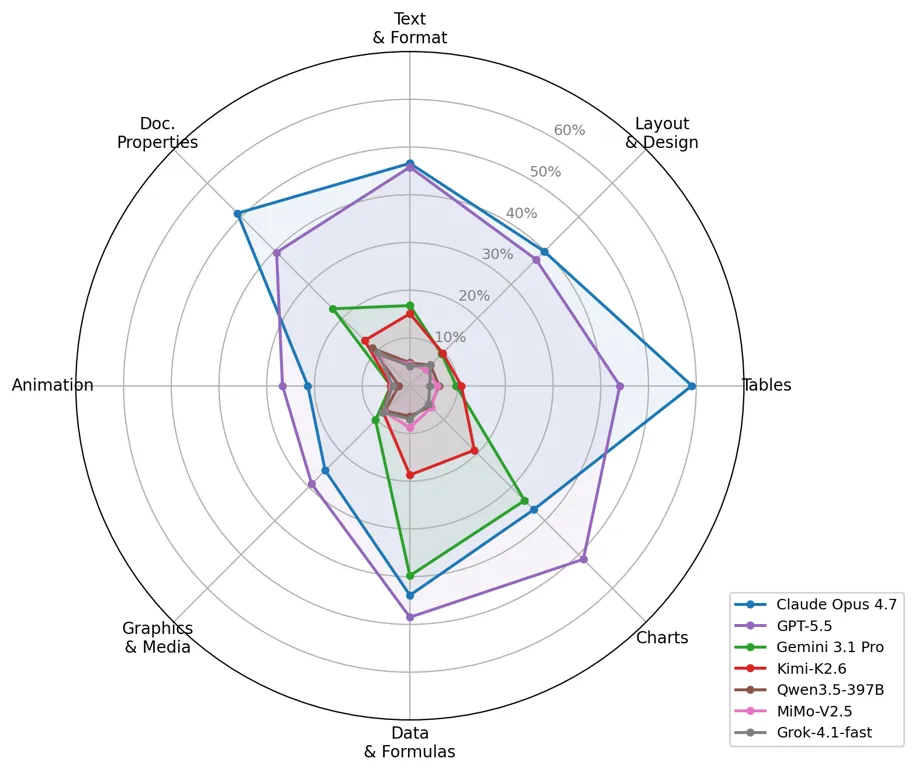
纵观三大办公应用,大模型表现出了明显的“偏科”特征:Excel 最容易,Word 居中,而 PPT 最难。Excel 的任务主要围绕公式、数据和图表展开,相关的参数和逻辑往往直接写在题面上,易于模型捕捉。相比之下,PPT 则是名副其实的“硬骨头”。它要求生成极其精确的内部常量与 XML 属性(例如实现某种特定的“陀螺旋”动画效果)。这些底层的实现知识在题面上从未提及,AI 很难凭借通用经验猜测准确。
从细分的 8 类核心技能来看,大模型的弱点更加明显。其中,动画(Animation)与图形媒体(Graphics & Media)的最高通过率仅为 26.7% 和 29.1%;而在图表(Charts)与数据公式(Data & Formulas)类任务上,通过率则分别达到了 51.4% 和 48.5%。
那么,当 AI 面对这些难题时,它们究竟是怎么丢分的?通过对错误根因的深度拆解,研究员们发现了一个有趣的现象:随着作答模式从单轮裸考升级到智能体开机考,扣分点发生了戏剧性的转移。
在单轮设置下,大模型的主要问题是程序崩溃。以 Claude Opus 4.7 为例,其失分有 51.8% 来自“代码执行失败”,由于语法或环境问题,程序根本没有跑起来。剩下的失分则主要归咎于实现知识错误(29.8%)以及操作缺失或误解(17.3%)。
当换上编程智能体模式后,代码崩溃的比例急剧下降至 7.9%。由于程序终于能够顺利运行,原本被崩溃掩盖的细节错误开始大量暴露,实现知识错误的占比反而飙升至 89.7%。
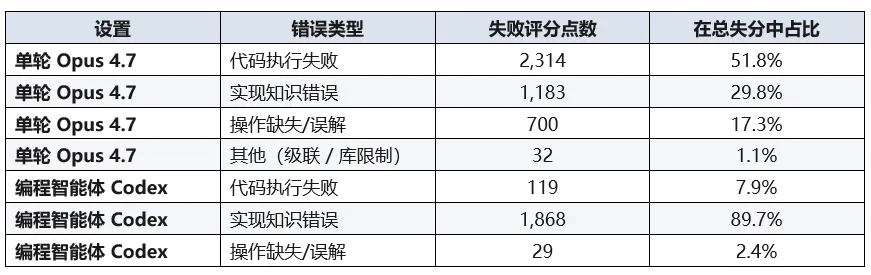
深入探究这些实现知识错误可以发现,AI 的痛点集中在底层表示对不上。无论是 OOXML 属性路径、枚举常量、主题颜色还是图表布局,AI 都极易因猜测而错位。例如,题目要求使用 Word 的内置页脚模板,但大模型放着系统现成的 API 不调用,非要大费周章地用基础代码从头重新拼装出一个模板。

看见人机协同的未来
通过这场严苛的国家级等级考试,大模型暴露了在办公自动化领域的局限性。究其根源,阻碍 AI 完美攻克 Office 任务的核心痛点并非模型参数量不够大,而是卡在以下三个鸿沟上:
- 样式库 vs API 常量的天然断层。人类用户在日常操作时,只需在可视化菜单中轻点两三下鼠标即可完成复杂的排版;但 AI 作为代码生成者,却必须精准背诵并写出那些在题面上从未出现过、隐藏在底层的复杂内部常量。
- 缺乏实时的视觉反馈机制。目前的 AI 大多处于“闭眼”写代码的状态。在缺乏图形界面感知的情况下,上一步操作的轻微偏差或失败,极易引发下游任务一连串的级联崩溃,而模型在执行过程中对此却一无所知。
- 迭代过程中“越改越错”的回退现象。编程智能体在面对报错、反复修改代码时,常常会顾此失彼,在修补新 Bug 的同时会把原本已经做对的部分意外改坏。数据显示,Codex 在 11.5% 的任务中,其智能体版本的最终表现反而退化到了比单轮版本还要低的水平。
OfficeEval 的这场“大考”让我们清醒地看到,通往完全办公自动化的道路依然充满荆棘。单纯依靠把模型做大或盲目拉长智能体的思考轮次,并不能从根本上解决问题。未来的突破口在于如何为 AI 引入运行时的状态检查、实时的视觉反馈闭环以及防回归机制,让模型能够看屏操作。当学术界与工业界的评测开始驶入追求绝对精准的真实社会任务时,这些差距为下一代人机协同办公系统的演进指明了方向。
Mind the Gap: Can Frontier LLMs Pass a Standardized Office Proficiency Exam?