

By Kinam Kim, Namiko Saito, Heecheol Kim, Katsushi Ikeuchi, Jaegul Choo and Yasuyuki Matsushita
Introduction
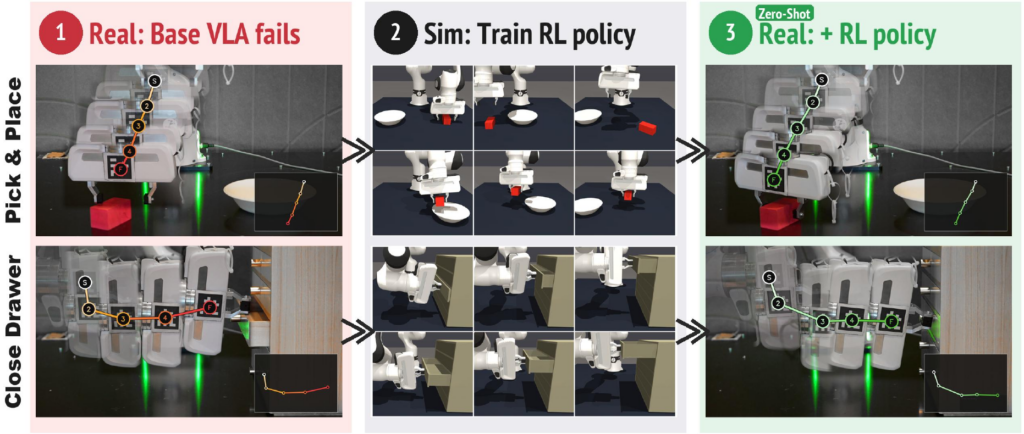
Vision-Language-Action (VLA) models enable broad manipulation capabilities by leveraging large-scale pretraining and robot demonstrations. However, imitation learning can cause small execution errors to accumulate over time, pushing the robot into states that demonstrations did not cover well.
Therefore, we present an object-centric residual reinforcement learning framework that enhances a frozen base VLA without real-world RL. We train a lightweight residual policy entirely in simulation and condition it on object-centric state, proprioception, and the base VLA action rather than raw images. As a result, this observation interface lets the residual transfer zero-shot to the real robot while avoiding the visual sim-to-real gap that affects image-based residuals.
Across five real-robot manipulation tasks, the simulation-trained residual improves average real-robot success from 42% to 76%. In addition, we show that successful residual-corrected rollouts can retrain the base VLA, enabling a self-improvement loop without additional teleoperation.
Method
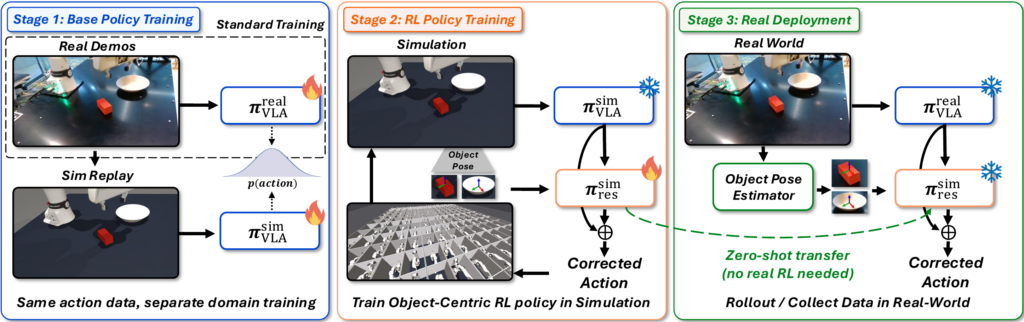
Stage 1 : Paired Sim/Real VLA via Teleoperation Replay. We start from a VLA trained on real-robot demonstrations, then replay the same teleoperation actions in simulation to train a simulation counterpart. Because identical action trajectories supervise both the real and simulated VLAs, their action distributions remain aligned despite different visual domains.
Stage 2 : Object-Centric Residual RL. Next, we train the residual policy in simulation on a compact observation consisting of 6-DoF task-relevant object poses, proprioception, and the current base VLA action. Pose noise injection and pose dropout make the residual robust to real-world pose-estimation errors.
Stage 3 : Zero-Shot Real Deployment. Finally, at deployment, the real VLA replaces the simulated VLA, and we add the same residual to the base action at every timestep. Since the residual does not observe images, the simulation need not look visually realistic; moreover, deployment requires no real-world RL, distillation, or residual-policy fine-tuning.
Real-Robot comparison
The following videos demonstrate our real-world robot experiments. The baseline VLA fails in the video on the left, whereas the residual framework successfully completes the task on the right.
Cube Lift


Pick and Place


Stack Cube


Stand Cup Up


Main results
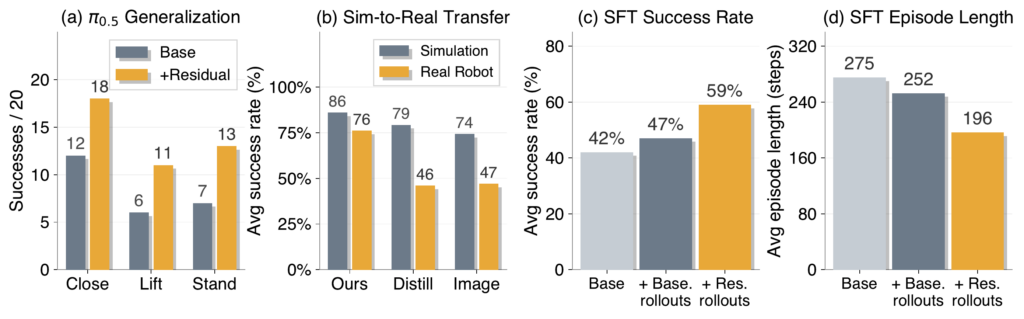
Success rates in simulation and real-robot evaluation. We report simulation results as mean ± standard deviation over three seeds. Meanwhile, real-robot results report successes out of 20 trials.
| Task | Simulation base | Simulation + residual | Real robot base | Real robot + residual |
|---|---|---|---|---|
| Cube Lift | 4.3 / 20 ± 0.6 | 20.0 / 20 ± 0.0 | 7 / 20 | 17 / 20 |
| Pick-and-Place | 7.0 / 20 ± 2.6 | 17.0 / 20 ± 2.0 | 9 / 20 | 16 / 20 |
| Stack Cube | 10.0 / 20 ± 1.0 | 14.7 / 20 ± 0.6 | 7 / 20 | 15 / 20 |
| Close Drawer | 11.3 / 20 ± 3.2 | 19.7 / 20 ± 0.6 | 14 / 20 | 20 / 20 |
| Stand Cup Up | 5.3 / 20 ± 1.2 | 14.7 / 20 ± 1.2 | 5 / 20 | 8 / 20 |
| Average | 7.6 / 20 ± 1.7 | 17.2 / 20 ± 0.9 | 8.4 / 20 | 15.2 / 20 |
Analysis
To better understand the advantages of our residual framework over the baseline, we conducted a series of quantitative analyses. The charts below highlight the specific improvements in efficiency and generalization.
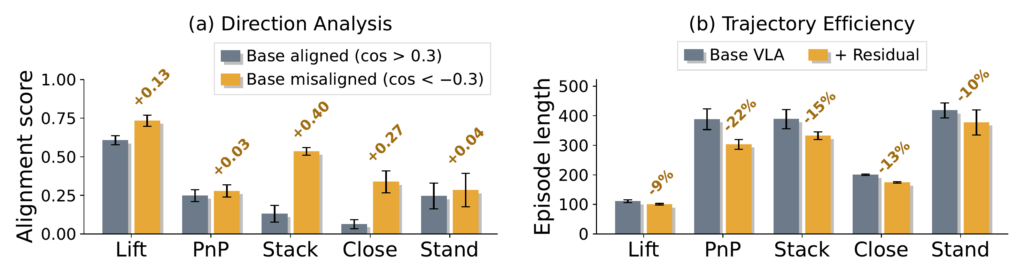
Action correction
The arrows show the base VLA action, the residual correction, and the combined action. When the base action becomes misaligned, the residual steers it back toward the goal.

Conclusion and future work
Object-centric residual RL combines the generalization ability of VLAs with the precise corrective capability of reinforcement learning. By choosing an observation interface that works in both simulation and reality, we can train the residual entirely in simulation and deploy it zero-shot on the real robot. As a result, the method improves manipulation performance without requiring real-world RL, distillation, or residual-policy fine-tuning.
Beyond direct deployment, the residual-corrected policy also produces better real-robot rollouts. These rollouts can retrain the base VLA and convert task-specific residual corrections into standalone policy improvements. In this way, residual RL can serve not only as an inference-time correction module, but also as a mechanism for generating higher-quality supervision.
Finally, future work includes extending the approach to more cluttered scenes and broader task families. It will also be important to develop more autonomous mechanisms for identifying which task-relevant objects should condition the residual policy. Ultimately, we view object-centric residual RL as one step toward robot learning systems that can use simulation to improve real-world behavior with less human intervention.