

近年来,很多大模型都能从自然语言描述中稳定地写出单个函数或单个文件。但如何将这种能力延伸到“从高层规格生成完整仓库”,或者“对真实仓库形成持续可用的全局理解”,目前仍处于早期阶段。而这两个看似相互独立的方向,实则共享着同一个底层困局——缺少一种适合代码仓库的中间表示。
目前主流的AI智能体框架普遍依赖三类代偿性表示:
- 自然语言计划:如MetaGPT、ChatDev 等多智能体系统让不同角色通过自然语言进行协商。但自然语言的歧义性往往会导致长程规划在迭代中逐渐漂移。
- 依赖图:通过静态分析得到的引用与调用(import/ call)拓扑。这种方式虽然结构清晰,却缺少”为什么这些代码会组织在一起”的功能语义。
- API 文档:语义丰富,但缺少全局拓扑结构,不足以驱动跨文件的导航与编辑。
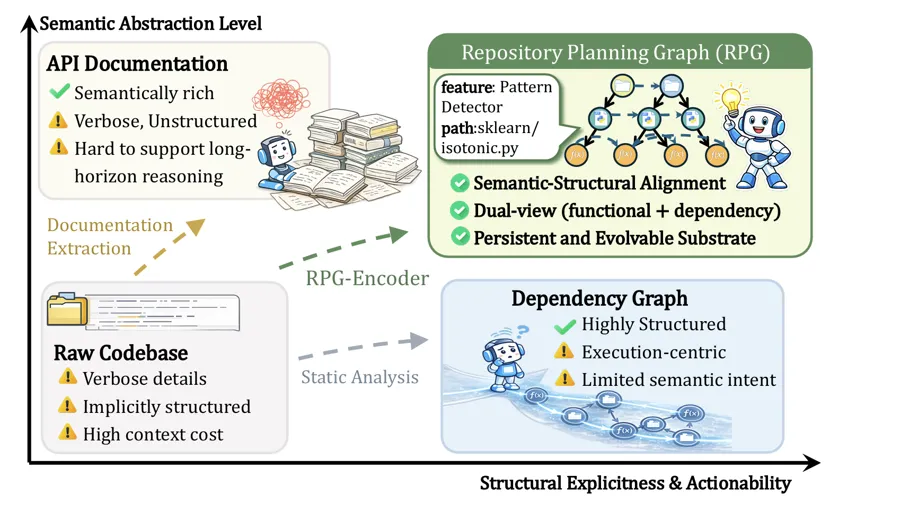
由此可见,这三种表示方式在某一维度上各自可用,却都无法构成一个同时具备语义密度与拓扑严谨性,且双向可达的统一基底。基于这一洞察,微软亚洲研究院的研究员们提出了两个方向相反但互为补充的配套工作:正向的RPG(Repository Planning Graph)瞄准“从零生成一个完整仓库”的长程任务;反向的RPG-Encoder 则瞄准了“已有仓库的理解、定位、修改与持续维护”。
两项工作围绕同一种结构化图表示(RPG)展开,一个负责”从需求生成代码”,另一个负责”从代码反推规划,并在其上做长期推理”,共同构成了一个完整的闭环。
为了让这一闭环真正落地,研究员们进一步将其封装进了开源工具 RPG-Kit。对编程智能体而言,优秀的软件规划不应只是聊天中“一瞬即逝的非结构化文本(transient chat artifact)”,而应当是有依据、可验证且可复用的“结构化实体”。RPG-Kit 正是将动态的生成计划固化为持久的图结构。
简而言之,如果说 RPG 负责将自然语言需求转化为仓库级规划,RPG-Encoder 负责将已有代码仓库逆向压缩回同一种规划表示,那么 RPG-Kit 则把RPG变成了面向真实变成智能体的控制层,让 Claude Code、GitHub Copilot 等前沿智能体可以围绕同一张持久图,不断进行规划、代码生成、仓库理解与图感知编辑。目前,RPG-Kit已在 GitHub 上开源了论文代码。
RPG项目系列链接:https://github.com/microsoft/RPG-ZeroRepo (opens in new tab)
相关论文已整理于文末,欢迎点击相关链接,了解更多技术详情。
RPG:从零生成完整仓库的”蓝图”
在“从零生成完整仓库”的任务中,智能体需要独立完成模块划分、文件拆分、接口设计、数据流定义到具体函数实现的完整链路。在此过程中,自然语言计划往往在 4–5 轮迭代后就会开始漂移和断裂,导致模块无法吻合,整个仓库变成一堆碎片。
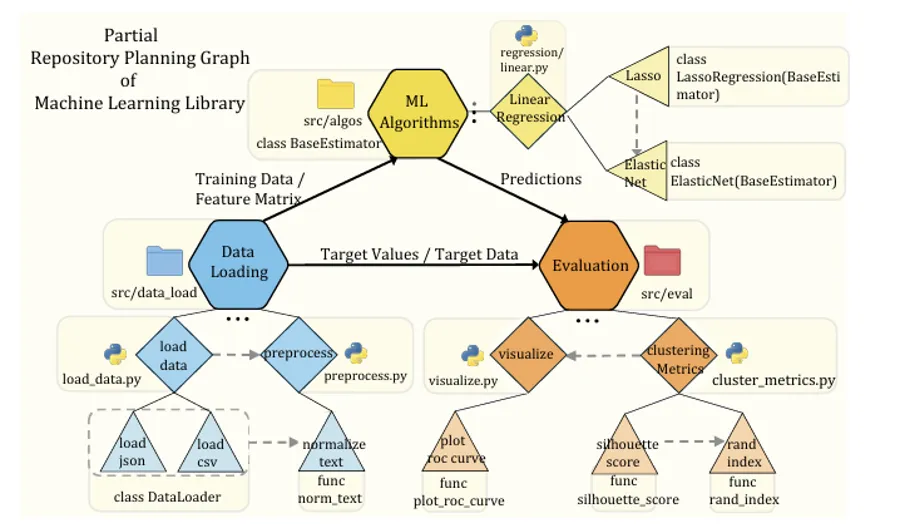
RPG 的核心思路是将规划的载体从自然语言替换为结构化的图表示。作为一种对仓库做”语义 + 实现”双视图编码的图表示,RPG的每个节点都同时承载了两层信息:在功能层上,它代表高层模块(如 algorithms)、中层组件(如 regression)或具体算法、类、函数;在结构层上,它对应实际的目录、文件或代码定义。两层在同一节点上完全对齐。
同时,图中的边也分为两类:跨模块的“数据流边”用于刻画输入与输出的依赖关系,模块内的“文件顺序边”则刻画同一模块下文件的执行顺序。这种双视图特性是RPG区别于传统表示方式的根本所在。
为了高效利用这一表示,研究员们设计了 ZeroRepo 三阶段流水线,将复杂的生成过程拆解为可控的图操作:
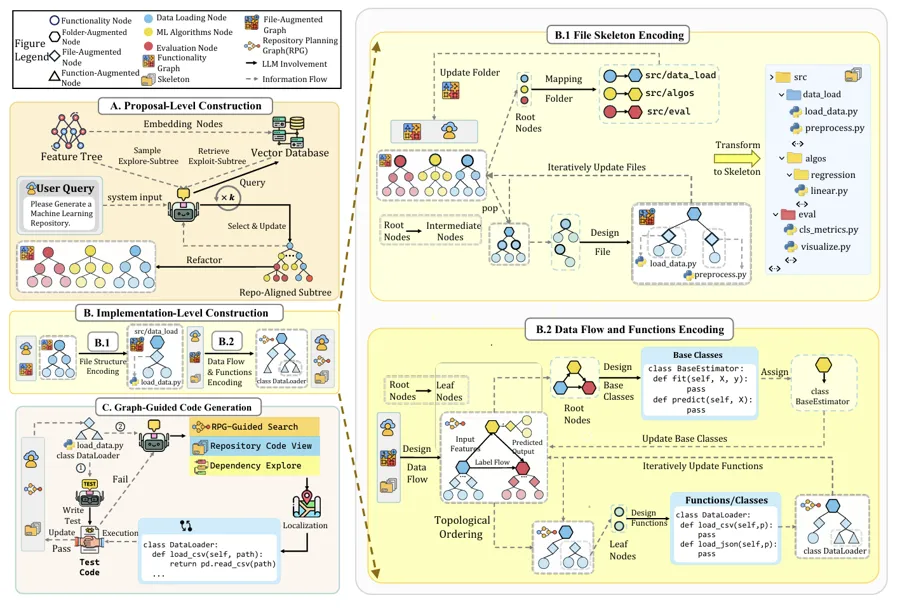
- 提案级构建(Proposal-Level Construction):将自然语言需求解耦并映射为一棵自顶向下的语义功能树,顶层是仓库目标,中层是模块边界,底层是可实现的功能单元,从而在结构化先验上完成系统功能框架的检索与枚举。
- 实现级构建 (Implementation-Level Construction): 把抽象的语义功能树进一步扩展为具象的仓库级实现蓝图。该阶段专注于明确文件结构、确定模块职责、规范接口抽象、定义数据流关系与依赖约束,为后续代码生成确立确定性的演进路径。
- 图引导代码生成(Graph-Guided Code Generation):按照拓扑顺序遍历 RPG,对每个叶节点执行测试驱动开发,并提供基于图的定位与逐层测试验证。
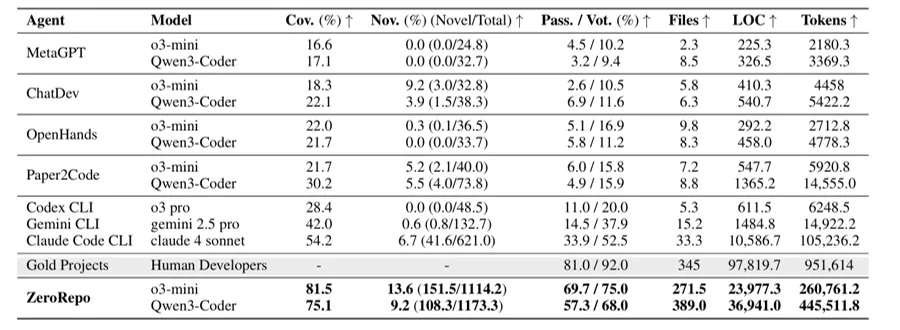
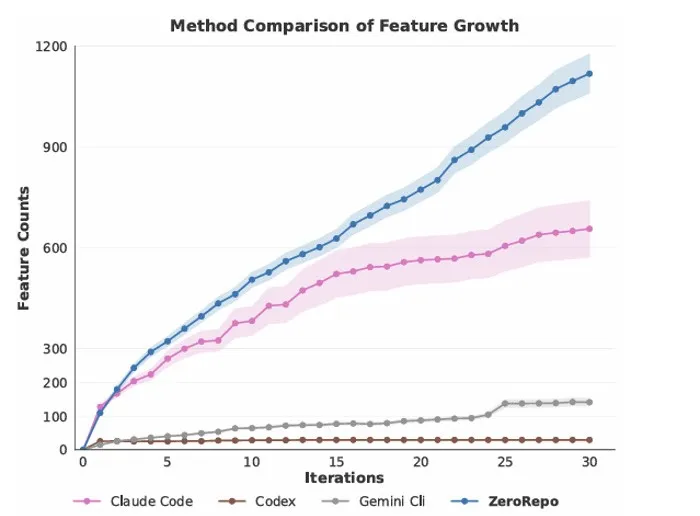
为了评估该流水线,研究员们构建了基于 6 个真实 Python 项目(scikit-learn、pandas、sympy、statsmodels、requests、django)的基准RepoCraft,共包含1052 个执行式任务。实验结果表明,ZeroRepo 实现了 81.5% 的功能覆盖率与 69.7% 的测试通过率,其生成的仓库平均规模约为 Claude Code 基线的 3.9 倍,并展现出近线性的代码量增长(线性拟合 R² = 0.97)。相比之下,自然语言计划基线在 4–5 轮迭代后便陷入停滞。
实验进一步发现,这种出色的可扩展性并非源于 prompt 技巧,而是来自 RPG 结构本身——即便去掉 EpiCoder Feature Tree 这一外部知识库,ZeroRepo 仍然保持线性增长。
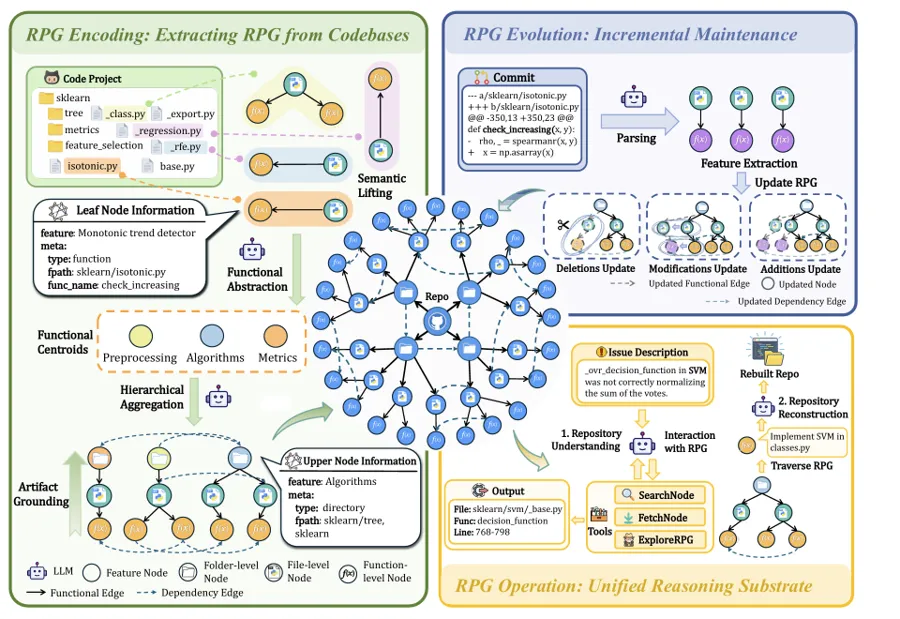
RPG-Encoder:让已有仓库逆向重构
在真实的软件工程场景中,开发者更多面对的是已有仓库的维护与重构。此时智能体面临的核心挑战是”该改哪里”以及如何随仓库每天的提交持续维护一份准确的全局理解。RPG-Encoder正是为了解决这一痛点,其核心逻辑在于:生成是将意图扩展为实现,而理解则是将实现压缩回意图。生成与理解是同一推理循环中的逆过程。
为了从已有代码中反推出同一种 RPG,RPG-Encoder 将过程拆分为Encoding 三阶段:
- 语义提升(Semantic Lifting ):利用大语言模型为每个代码实体(如函数或类)生成一组原子的动宾特征(atomic verb-object features),例如 validate token、load config等,把不同文件、不同风格的代码统一到一致的语义粒度上。
- 语义结构重组(Semantic Structure Reorganization):找出仓库的架构性质心(centroid),如 DataProcessing或ModelTraining,并将所有低层节点按语义贴近度自下而上归位,重新组织成三层功能结构。
- 产物锚定(Artifact Grounding):把每个抽象子树锚定回它对应的物理目录,并通过 AST 分析补上 import/ call 等依赖边。
通过这种方式反向恢复出来的 RPG,与 ZeroRepo 正向生成的图在结构上完全一致,两者拥有相同的双视图节点、功能边与依赖边。
由于任何高层抽取都会带来信息损失,所以研究员们在 RepoCraft 上设计了一个对照重建实验,以验证 RPG 的信息保留能力:让 ZeroRepo 分别基于”官方 API 文档”和”RPG-Encoder 抽取出的 RPG”去重建同一组目标仓库。
结果显示,在 GPT-5-mini 上,基于 RPG 的重建达到 98.5% 的功能覆盖率与 86.0% 的通过率,恢复了接近原仓库规模的代码体量;而基于传统文档的重建仅恢复了约 17% 的代码体量。这证明了RPG 抽取的图在结构与高层语义上保留了足以驱动高度还原重建所需的关键信息,相比 API 文档更加紧凑且可逆。

演化与操作:让蓝图持续可用
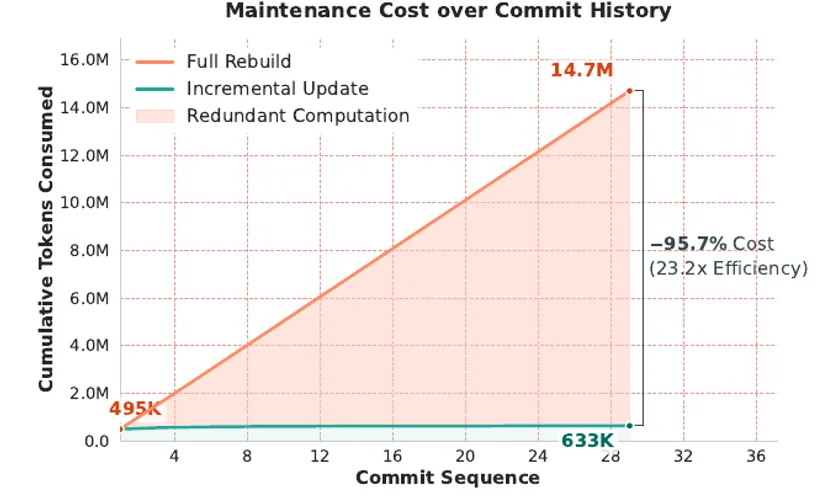
真实的仓库每天都在发生变更,如果每次提交(commit) 都需要全量重抽,其计算成本将随仓库规模呈线性堆积。为了让蓝图持续可用,RPG-Encoder 设计了提交级(commit-level)的差分维护机制。该机制将每次变更分解为删除、修改、增添三种原子更新。其中”修改”操作仅在大语言模型检测到节点的功能意图发生迁移时才触发结构性重排,从而避免了微小的实现改动引发昂贵的层次迁移。
在一系列真实的 commit 序列对比中,全量重建累计消耗 14.7M tokens,而增量更新只消耗 633K tokens,降本 95.7%,且在 SWE-bench Live 上的定位精度与全量重建基本持平。这标志着 RPG 从一个静态的快照升级为了可长期维护的动态表示。
同时,RPG还被开放为智能体的统一推理基底。研究员们对外提供了三个原生工具:SearchNode(按语义或元数据全局检索节点)、FetchNode(获取节点完整源码与属性)、ExploreRPG(沿功能边或依赖边遍历)。借助这些工具,智能体不再需要直接面对原始仓库的全部噪声,而是可以在 RPG 上进行高效导航。
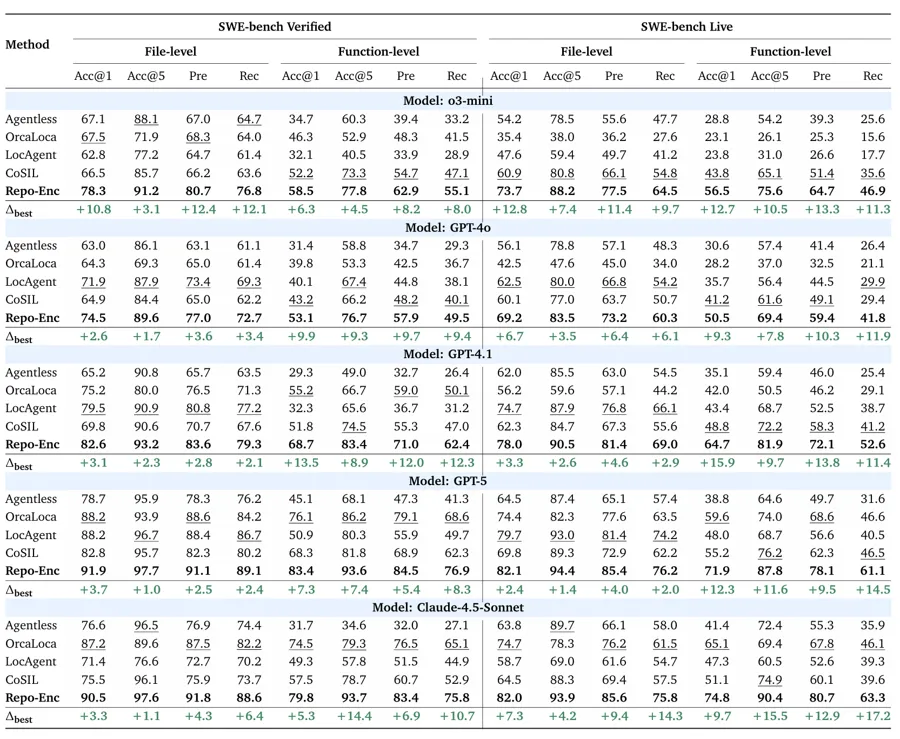
需要强调的是,在SWE-bench Verified 与 SWE-bench Live Lite 的评估中,该工作专注于代码定位(localization)任务,即给定一个 issue 描述,模型预测需要修改的文件或函数集合。在这项任务中,RPG-Encoder 配 Claude-4.5-Sonnet 在 SWE-bench Verified 上取得了 93.7%的Function-level Acc@5,比最强基线 OrcaLoca 高出 14.4 个百分点;在 SWE-bench Live Lite 上配 GPT-5 取得了87.8%的准确率,比 CoSIL 高出 11.6 个百分点。同时,它在所有主流模型底座上的性价比(Acc@5 / Cost)位列第一。
在实验中,研究员们还观察到了一个有趣的 “Search-then-Zoom” 模式。越强大的 推理模型越可以把 RPG 当作全局地图使用。模型会先通过 ExploreRPG或SearchNode 建立全局视图,再用 FetchNode 收敛到细粒度的代码段。这表明 RPG 并非一个简单的辅助技巧,已经成为推理本身的重要基底。
闭环:一个表示,两个方向
把两项工作放在一起看,整个技术叙事变得非常清晰:RPG 提供了从意图到代码的正向通路;RPG-Encoder 提供了从代码到RPG的反向通路,以及在 RPG 之上的演化与操作。同一种图结构,两个相反的方向,构成了代码大模型在仓库级工程上的推理闭环。
这一思路在计算机历史上有一个对照——编译器领域的中间表示(IR)。正是因为有了中间表示,才使得“N 种语言 × M 种架构”的繁琐翻译不必再编写 N × M 个翻译器,而是降维成 N 个前端 + M 个后端的经典工程问题。
如今,软件工程智能体同样面临着“N 种任务 × M 种仓库”的组合,涵盖从零生成、bug 定位、特性添加、增量重建、跨任务推理、文档生成、回归测试等等。如果每一对组合都依赖全新的 prompt 和 pipeline 单独解决,那么整个系统的复杂度将无法收敛。而一种仓库级的中间表示正是实现降维的关键。RPG 与 RPG-Encoder 共同提出的,恰恰就是这样一种 IR:它对生成可读,对理解可写,对演化可改,对推理可查。
RPG 与 RPG-Encoder 是微软亚洲研究院在仓库级软件智能方向上的连续投入,其前置工作还包括提供了 150 万个节点功能本体的 EpiCoder。目前RPG 与 RPG-Encoder两项工作的代码、论文与项目页面也均已开放。RPG 的承载力还远未被穷尽,欢迎社区在这一表示之上探索更多任务,并展开深入的交流与合作。
RPG: A Repository Planning Graph for Unified and Scalable Codebase Generation(已被ICLR 2026接收)
论文链接:https://arxiv.org/abs/2509.16198 (opens in new tab)
RPG-Encoder: Closing the Loop: Universal Repository Representation with RPG-Encoder(已被ICML2026接收)
论文链接:https://arxiv.org/abs/2602.02084 (opens in new tab)
RPG项目系列链接:https://github.com/microsoft/RPG-ZeroRepo (opens in new tab)