

At a glance
- AI agents often fail because their instructions, or skills, are manually modified with no guarantee of improvement. SkillOpt turns skill editing into a training process, making agent behavior more reliable without changing model weights.
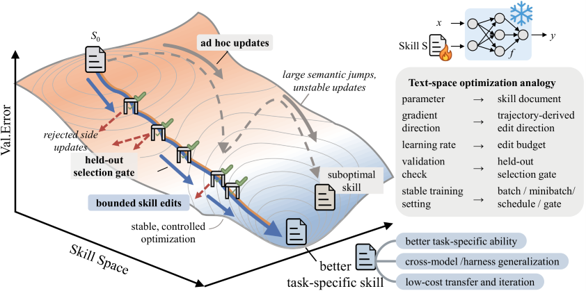
- SkillOpt treats an agent skill file as a trainable parameter outside a frozen target model, turning skill writing from one-shot prompting into a controlled optimization process.
- Across six benchmarks, seven target models, and three execution modes, SkillOpt is the best or tied-best method in all 52 evaluation cells, improving performance without updating model weights.
- SkillOpt keeps skills compact and auditable through bounded text edits, validation gating, rejected-edit feedback, and slow/meta updates, avoiding uncontrolled prompt drift.
- The optimized skills transfer across model scales, agent harnesses, and related tasks, suggesting that they capture reusable workflow knowledge rather than benchmark-specific instructions.
Large language models (LLMs) are increasingly deployed as agents that gather evidence, call tools, and execute multi-step tasks. For these agents, the hard problem is no longer whether they can call a tool, but whether they can complete tasks reliably and consistently. Today, agent skills typically come from three sources: experts write them by hand, a frontier model generates them one-shot, or the agent loosely revises them after execution. None of these approaches behaves like a deep-learning optimizer. They lack step-size control, held-out validation, and any memory of revisions that failed. As a result, skills tend to grow longer and drift with each rewrite, and a revision that seems perfectly reasonable can quietly degrade real task performance. This uncontrolled skill evolution has become a major obstacle on the path from agent prototype to dependable, production-grade deployment.
In our recent paper, SkillOpt: Executive Strategy for Self-Evolving Agent Skills, we reframe the question from “how do we write a better prompt?” to “how do we train the skill?” SkillOpt treats the skill file as a trainable parameter living outside a frozen target model, bringing a training-style optimization loop, consistent gains across 52 evaluation cells, and a compact skill file that stays readable, auditable, and transferable.
How SkillOpt works
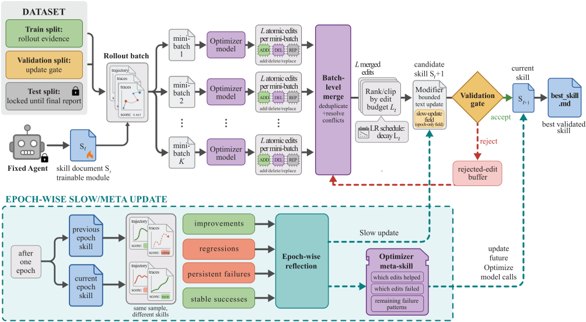
SkillOpt organizes skill editing as a forward–backward–update cycle in text space. In the forward pass, the frozen target model executes a batch of training tasks with the current skill; the rollout batch size controls how much evidence each update receives. In the backward pass, a separate optimizer model reads the resulting trajectories in reflection minibatches, distilling patterns to preserve from successful trajectories and patterns to correct from failures.
In the update step, the optimizer proposes small add, delete, and replace edits; candidate edits are merged, deduplicated, ranked, and clipped by a textual learning rate—a per-step edit budget. Every candidate skill must then pass a strict validation gate: it is adopted only if it scores strictly higher than the current skill on the held-out validation split. Rejected edits are not discarded; they enter a rejected-edit buffer that serves as negative feedback for later optimizer calls in the same epoch. On a slower cadence, an epoch-wise slow/meta update consolidates longer-horizon lessons that single batches cannot reveal (Figure 2). Together, bounded edits, validation gating, and best-version selection keep skill optimization controllable and auditable, so the skill converges instead of drifting.
Consistent gains across benchmarks, models, and execution modes
We evaluated SkillOpt across six benchmarks (SearchQA, SpreadsheetBench, OfficeQA, DocVQA, LiveMathematicianBench, and ALFWorld), seven target models from frontier-scale GPT-5.5 to the small open-weight Qwen3.5-4B, and three execution modes (direct chat, Codex, and Claude Code). Counting each combination as one evaluation cell, When measured against human-written skills, one-shot LLM skills, Trace2Skill, TextGrad, GEPA, and EvoSkill, SkillOpt delivered the best or tied for -best results on all 52 cells. These performance improvements are unusually large for a method that updates no model weights. With GPT-5.5 in direct chat, SkillOpt raises the six-benchmark average from 58.8 to 82.3, a +23.5-point absolute improvement—and +5.4 points above an oracle that picks the single best competing method per cell. The largest gains appear on procedural benchmarks: SpreadsheetBench rises from 41.8 to 80.7, OfficeQA from 33.1 to 72.1, and LiveMathematicianBench from 37.6 to 66.9. The same interface carries over to agentic loops, lifting GPT-5.5 by +24.8 points inside Codex and +19.1 inside Claude Code over no skill.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
A small model plus a skill file
Approaching the next model tier SkillOpt also narrows the gap between small or open-weight models and frontier models—without changing any weights or adding any extra model calls at inference. After optimization, GPT-5.4-mini’s six-benchmark average (64.3) exceeds the no-skill baseline of the larger GPT-5.4 (59.7), and GPT-5.4-nano (57.4) exceeds the no-skill baseline of GPT-5.2 (51.3). Qwen3.5-4B, a 4-billion-parameter open-weight model, surpasses GPT-5.2’s no-skill baseline as well. Gains that once required a larger model can now be approximated by one optimized skill file.
Skills that transfer: train once, reuse everywhere
The optimized skill file captures reusable task-solving procedures rather than instructions overfit to a single model, benchmark, or execution environment. This is why the same skill can still improve performance when transferred across model scales, agent harnesses, and related tasks. In our transfer experiments, skills continued to deliver gains when moved across model scales, across execution harnesses, and to a nearby math benchmark. The clearest example is cross-harness transfer: a spreadsheet skill trained inside Codex, dropped into Claude Code with no further optimization, lifts the no-skill baseline from 22.1 to 81.8 (+59.7)—slightly above the 80.4 achieved by training directly inside Claude Code. Because the two harnesses expose different tool surfaces, this suggests SkillOpt learns general workflow logic, not just harness-specific recipes.
Compact, readable, and built from very few accepted edits
The deployed artifact, best_ skill.md , is neither an opaque parameter blob nor an ever-growing log. Across six case studies, the median final skill length is roughly 920 tokens, and because the validation gate rejects most proposals, only one to four edits are accepted into the final file. OfficeQA’s +39.0-point gain comes from a single accepted edit. The learned rules read like a seasoned practitioner’s advice. Component ablations confirm that the controls do the work: removing the rejected-edit buffer lowers scores on all three ablation benchmarks, and removing both the meta skill and the slow update drops SpreadsheetBench from 77.5 to 55.0. A new adaptation layer for the agent era SkillOpt points to a lighter-weight path for domain-adapting agents: instead of fine-tuning weights, hard-coding task logic, or hand-tuning prompts, teams can train a small, versionable, auditable natural-language skill layer—wherever automatic evaluation or a reliable verifier exists.
By bringing learning rates, schedules, validation splits, rejected samples, and slow updates to agent skills, SkillOpt suggests that training need not be limited to model weights. Procedural knowledge outside the model can also be optimized.
When that process is controlled, validated, and recorded, a natural-language skill becomes a stable, transferable, and reversible adapter between frontier-model capability and real-world workloads. Read the full paper, visit the project page at aka.ms/skillopt (opens in new tab), or explore the SkillOpt GitHub repository at github.com/microsoft/SkillOpt (opens in new tab). Teams building agentic workflows can use SkillOpt as a foundation for training reusable skills against their own tasks and verifiers. See also our companion project, SkillLens.