


Milan-X CPU を搭載した HBv3 VM のパフォーマンスとスケーラビリティ
2021.12.07 Azure – HPC
Share this page on
寄稿者: Amirreza Rastegari、Jon Shelley、Jithin Jose、Evan Burness、Aman Verma
3D V-Cache を搭載した AMD EPYC の第 3 世代プロセッサ (コードネーム “Milan-X”) で強化された Azure HBv3 VM のプレビュー プログラムが開始されました。こちらのブログでは、これらの新しい VM についての詳細な技術情報、プレビュー プログラムで利用する際にお客様が期待できること、この機能の一般提供が開始される時期について紹介します。
これらの強化された VM は、標準の EPYC 第 3 世代 “Milan” プロセッサを搭載した、一般提供が開始されている現行の HBv3 VM と比較して、以下のような特徴を備えています。
- CFD ワークロードにおけるパフォーマンスが最大 80% 高い
- EDA RTL シミュレーション ワークロードにおけるパフォーマンスが最大 60% 高い
- 陽解法有限要素解析におけるパフォーマンスが最大 50% 高い
また、Milan-X プロセッサを搭載した HBv3 VM は、ワークロードのスケーリング効率も大幅に向上しており、最大で 200% に達し、広範なワークロードとモデルにわたってほぼ線形を維持します。
HBv3 VM – VM サイズの詳細と技術概要
Milan-X プロセッサを搭載した HBv3 VM は、以下のサイズで提供されています。
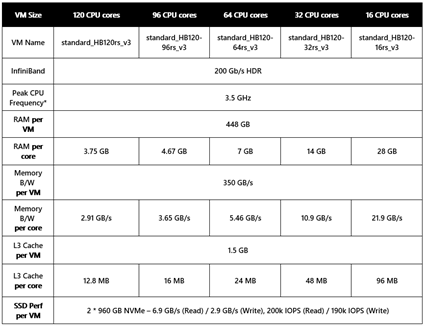
これらの VM は、Azure で一般提供されている標準の AMD EPYC 第 3 世代プロセッサ (コードネーム “Milan”) を搭載した、現在利用可能な HBv3 VM と多くの共通点がありますが、主要な例外として、異なる CPU (Milan-X) が使用されていることが挙げられます。完全な仕様は以下のとおりです。
- 最大 120 の AMD EPYC 7V73X CPU コア(3D V-Cache を搭載した EPYC “Milan-X”)
- コアあたり最大 96 MB の L3 キャッシュ (標準の Milan CPU の 3 倍、"Rome" CPU の 6 倍)
- 350 GB/秒の DRAM 帯域幅 (STREAM TRIAD)、最大 1.8 倍の増幅 (最大 630 GB/秒の有効帯域幅)
- 448 GB の RAM
- 200 Gbps の HDR InfiniBand (SRIOV)、Mellanox ConnectX-6 NIC、アダプティブ ルーティング対応
- 2 x 900 GB の NVMe SSD (SSD あたり5 GB/秒 (読み取り) および 1.5 GB/秒 (書き込み)、ラージ ブロック IO)
HBv3 シリーズの仮想マシンのその他の詳細については、https://aka.ms/HBv3docs を参照してください。
Milan-X とはどのようなもので、どのようにパフォーマンスに影響するのか
Milan-X CPU に搭載されている 3D V-Cache と呼ばれるスタックド L3 キャッシュ テクノロジや、このテクノロジが広範な HPC ワークロードにどのような影響を及ぼすのか (または及ぼさないのか) について理解しておくことは有益です。
まず、Milan-X のアーキテクチャは、Milan コア、CCD、ソケット、サーバーあたりの L3 キャッシュ メモリが Milan の 3 倍であるという点のみが異なります。これにより、2 ソケット サーバー (基盤となる HBv3 シリーズ VM など) の合計は以下のようになります。
- (16 CCD/サーバー) x (96 MB L3/CCD) = 1.536 GB の L3 キャッシュ/サーバー
この L3 キャッシュの容量がどれだけ大きいかを示すために、2 ソケット サーバーあたりの L3 キャッシュに関して、過去 5 年間にわたって HPC のお客様によって幅広く使用されてきた複数のプロセッサ モデルと、HBv3 シリーズ VM に追加された Milan-X プロセッサを並べて比較してみます。

コンテキストを考慮せずに L3 キャッシュ サイズだけに目を向けると、惑わされる可能性があるので注意してください。CPU ごと、また世代ごとに、L2 (高速) と L3 (低速) の比率の配分が異なります。たとえば、Intel Xeon “Broadwell” CPU は、Intel Xeon “Skylake” コアよりもコアあたりの L3 キャッシュが (多くの場合 CPU も) 多いですが、メモリ サブシステムのパフォーマンスがより高いわけではありません。Skylake コアの L2 キャッシュは Broadwell CPU よりも大きく、また DRAM からの帯域幅も広くなっています。上の表は、単に、Milan-X サーバーの L3 キャッシュの合計サイズが以前の CPU と比べてどのくらい大きいかを示す目的で作成されたものです。
この大きさのキャッシュ サイズにより、(1) 有効メモリ帯域幅および (2) 有効メモリ待機時間を大幅に改善することが可能です。メモリ帯域幅やメモリ待機時間の改善により、多くの HPC アプリケーションで部分的または全面的にパフォーマンスが向上するため、Milan-X プロセッサが HPC のお客様に及ぼす潜在的影響は大きいと言えます。これらのカテゴリに分類されるワークロードの例を以下に示します。
- 数値流体力学 (CFD) – メモリ帯域幅
- 気象シミュレーション – メモリ帯域幅
- 陽解法有限要素解析 (FEA) – メモリ帯域幅
- EDA RTL シミュレーション – メモリ待機時間
ただし、これらの大規模なキャッシュの影響を受けない対象について理解することも同様に重要となります。具体的には、ピーク FLOPS、クロック周波数、メモリ容量は改善しません。したがって、これらの 1 つまたは複数の要因によってパフォーマンスまたは実行自体が制限されるワークロードについては、一般的に Milan-X プロセッサに搭載されている超大規模な L3 キャッシュの影響をあまり受けません。これらのカテゴリに分類されるワークロードの例を以下に示します。
- 分子動力学 – 高密度コンピューティング:
- EDA フル チップ設計 – 大容量メモリ
- EDA 寄生抽出 – クロック周波数
- 陰解法有限要素解析 (FEA) – 高密度コンピューティング
マイクロベンチマーク
こちらのセクションでは、Milan-X プロセッサへのアップグレードの一環として変更されている HBv3 シリーズの唯一の要素であるメモリ パフォーマンスのマイクロベンチマークに焦点を当てます。MPI パフォーマンスなどの他のマイクロベンチマーク情報については、2021 年 3 月に公開された Azure HBv3 VM での HPC パフォーマンスとスケーラビリティの結果を参照してください。
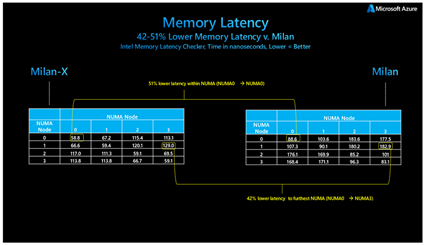
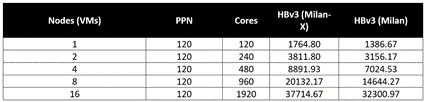
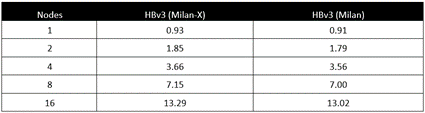
図 1: Milan-X および Milan プロセッサの基本的なメモリ待機時間の比較
上の図 1 は、メモリの待機時間と帯域幅を計測するためのツール Intel Memory Latency Checker (MLC) の実行結果を示しています。MLC は計測された待機時間をナノ秒単位で出力します。図 1 の右の表は Milan CPU (EPYC 7V13) を搭載した HBv3 シリーズ VM で実施された待機時間テストの出力を示しており、左の表は Milan-X CPU (EPYC 7V73X) で強化された HBv3 シリーズ VM で実施された同一テストの出力を示しています。
このテストでは、ベスト ケースの待機時間 (最短パス) が 51%、ワースト ケースの待機時間 (最長パス) が 42% 短縮されています。歴史的に見ると、これはメモリ コントローラーが CPU パッケージに移動して以来 10 年以上において、最大規模となるメモリ待機時間の相対的な改善となります。
ここで計測された結果は、Milan-X が DRAM アクセスの待機時間を短縮していることを意味しているわけではない点に注意してください。正しくは、より大規模なキャッシュによってテストのキャッシュ ヒット率が向上し、L3 と DRAM の待機時間の組み合わせによって小規模な L3 キャッシュよりも優れた効果的な結果が実現されます。
より大規模な L3 キャッシュを実現するために AMD で使用された独自のパッケージ方法 (垂直ダイ スタッキング) により、Milan プロセッサよりも L3 待機時間の分布の幅が広くなることにも注意してください。これは L3 メモリ待機時間が長くなるという意味ではありません。ベスト ケースの L3 待機時間は、Milan の従来の平面的な L3 パッケージ方法と同じです。ただし、ワースト ケースの L3 待機時間は多少長くなります。
メモリ帯域幅についても、同様の点と微妙に異なる点があります。業界標準の STREAM ベンチマークを一般的な設定で実行しました。具体的には、以下のコマンドを使用してこのベンチマークを実行しました。
これにより、STREAM-TRIAD に対して、最大 358 GB/秒という結果が返されました。
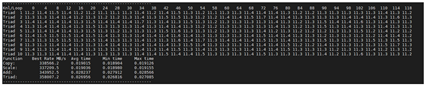
図 2: Milan-X プロセッサを搭載した HBv3 シリーズ VM での STREAM メモリ ベンチマーク
上記の結果は、標準の Milan CPU を搭載した HBv3 シリーズなど、チャネルあたり 1 DIMM の構成で 3,200 MT/秒の DIMM を使用する、Milan プロセッサを搭載した標準の 2 ソケット サーバーで計測された帯域幅と基本的に同じ帯域幅を示しています。また、STREAM テストの一環として実行された問題テスト サイズ (上記の 400000000) は大き過ぎてキャッシュには収まりません。したがって、厳密に言うと、実質的には DRAM パフォーマンスのテストになります。これらのサーバー上の物理 DIMM および CPU のメモリ コントローラーとの通信能力に差はないため、この結果は驚くことではありません。
ただし、下記の、アクティブなデータセットの大部分が大規模な L3 キャッシュ内に収まる、メモリ帯域幅が大幅に制限されたアプリで計測されたパフォーマンスが示すように、基準の Milan 2 ソケット サーバーと比較して、最大 80% のパフォーマンス向上が計測されています。したがって、ワークロードは DRAM から最大 630 GB/秒の帯域幅で供給されているかのように機能しているため、大規模な L3 キャッシュからの増幅効果は、有効メモリ帯域幅を最大 1.8 倍増大させると言えます。
繰り返しますが、以下のデータは、キャッシュから実行されるアクティブなデータセットの割合の増加とパフォーマンス向上が密接に関係していることを示しているため、メモリ帯域幅の増幅効果は「最大値」として理解しておく必要があります。したがって、たとえば 1 台の VM 上で実行されているワークロード A からの小規模 CFD モデル (200 万の要素など) では、モデルの大部分が L3 キャッシュ内に収まるため、最大 80% の潜在的パフォーマンス向上の大部分が即座に実現されます。一方、1 台の VM 上で実行されているワークロード A からの大規模 CFD モデル (1 億以上の要素など) では、パフォーマンス向上の割合が小さくなります (最大 7 ~ 10%)。ただし、ワークロードを複数の VM にスケールアウトすると、大規模なモデルでもデータの大部分が最終的にキャッシュに収まるため、潜在的パフォーマンス向上の最大値に近づいていきます。
アプリケーション パフォーマンス
特に記載がない限り、下記のすべてのテストは以下の構成で実施されているものとします。
- CentOS 8.1 HPC イメージ (Azure Marketplace で提供され、GitHub で管理)
- HPC-X MPI バージョン8.3
以下の VM がテストされています。
- 120 コアの AMD EPYC “Milan-X” プロセッサを搭載した Azure HBv3 (現在プレビューの段階、仕様については上記を参照)
- 120 コアの AMD EPYC “Milan” プロセッサを搭載した Azure HBv3 (完全な仕様)
- 120 コアの AMD EPYC “Rome” プロセッサを搭載した Azure HBv2 (完全な仕様)
- 44 コアの Intel Xeon Platinum “Skylake” を搭載した Azure HC (完全な仕様)
アプリケーション パフォーマンス
特に記載がない限り、下記のすべてのテストは以下の構成で実施されているものとします。
- CentOS 8.1 HPC イメージ (Azure Marketplace で提供され、GitHub で管理)
- HPC-X MPI バージョン8.3
以下の VM がテストされています。
- 120 コアの AMD EPYC “Milan-X” プロセッサを搭載した Azure HBv3 (現在プレビューの段階、仕様については上記を参照)
- 120 コアの AMD EPYC “Milan” プロセッサを搭載した Azure HBv3 (完全な仕様)
- 120 コアの AMD EPYC “Rome” プロセッサを搭載した Azure HBv2 (完全な仕様)
- 44 コアの Intel Xeon Platinum “Skylake” を搭載した Azure HC (完全な仕様)
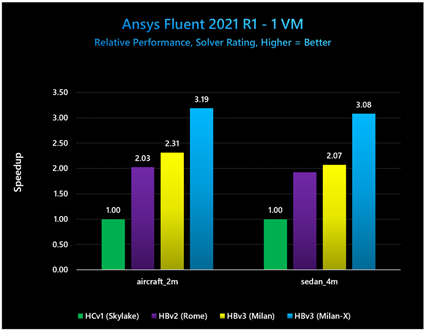
図 3: Ansys Fluent 2021 R1 で実行された小規模なモデルにおいて、Milan-X を搭載した HBv3 は、他のプロセッサを搭載した旧世代の Azure HPC VM と比較して、相対的パフォーマンスが大幅に向上していることを示している
これらのテストにおける正確なソルバー評価の出力は以下のとおりです。

aircraft_2m モデルと sedan_4m モデルにおける Milan-X と Milan の比較では、それぞれ 38% と 49% のパフォーマンス向上が見られます。
スケーリングが必要な中規模のモデルについては、aircraft_14m 問題を実施し、以下の相対的パフォーマンスの結果が得られました。

図 4: 中規模の Ansys Fluent モデルにおいて、Milan-X は VM が 8 台のときに最大のパフォーマンス向上を示している
これらのテストにおける正確なソルバー評価の出力は以下のとおりです。
この問題に関して、現行バージョンの Azure HBv3 も、プレビュー バージョンの Azure HBv3 も、16 台の VM まで極めて効率的にスケーリングします。また、1 台の VM におけるパフォーマンス レベルと比較した場合、Milan も Milan-X も超線形のスケーラビリティを実現しています (Milan-X は 134%、Milan は 146% のスケーリング効率)。さらに、中規模のモデルにおいて、VM が 8 台 (960 コア) のときにパフォーマンス向上の割合が最大の 37% となり、Milan-X のメリットが大きくなることがわかります。
次に、F1 レーシング カーの外気流をモデル化する、よく知られた大規模な f1_racecar_140 モデルを評価しました。
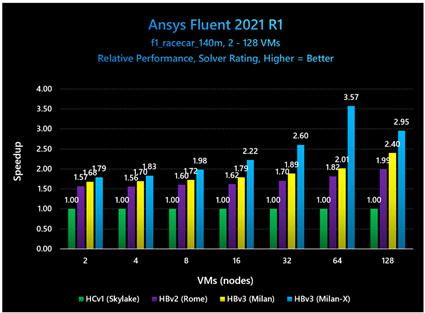
図 5: 大規模な Ansys Fluent モデルにおいて、Milan-X は VM が 64 台のときに最大のパフォーマンス向上を示している
これらのテストにおける正確なソルバー評価の出力は以下のとおりです。
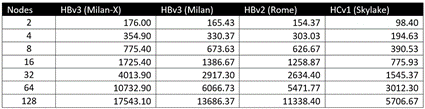
この難易度の高いモデルに関して、4 つの Azure HPC VM のいずれも、最大の計測スケールとなる 128 台の VM まで効率的にスケーリングします。これは、HPC 中心のプロセッサの選択、低ジッターのハイパーバイザー、および Azure での 100 Gb EDR (HC シリーズ VM) と 20 Gb HDR 200 ネットワーク (HBv3 および HBv2 シリーズ VM) の使用の組み合わせによるものです。
- Milan-X を搭載した HBv3: 156% のスケーリング効率
- Milan を搭載した HBv3: 130% のスケーリング効率
- Rome を搭載した HBv2: 115% のスケーリング効率
- Skylake を搭載した HC: 91% のスケーリング効率
CPU ごとの比較において、VM が 64 台のときに相対的差異が最大となっており、Milan-X が Milan と比べて 77%、Rome と比べて 96%、Skylake と比べて 257% 高いパフォーマンスを示しています。
全体的に見ると、Milan-X の相対的パフォーマンスがワーキング セットの大部分が各サーバーの L3 キャッシュに収まる間はスケールとともに向上するという、小規模モデルや中規模モデルで見られた傾向が続いていることを確認できます。相対的差異が最大となるのは小規模な問題においては VM が 1 台のとき、中規模のモデルにおいては VM が 8 台のときですが、大規模な 1 億 4,000 万セルの問題においては VM が 64 台のときに最大となります。
最後に、世界最大のスーパーコンピューターの一部で 145,000 を超えるプロセッサ コアまでスケーリングすることが示されている超大規模なモデル combustor_830m をテストしました。このモデルではこのレベルまでのスケーリングは実施していませんが、このような大規模なモデルでもスケールとともにパフォーマンスの差異が大きくなるパターンが発生するかどうか確認することもできます。

図 6: 大規模な Ansys Fluent モデルにおいて、Milan-X は VM が 128 台のときに最大のパフォーマンス向上を示しているが、未テストのより大規模なスケーリングでさらに向上する可能性がある
このモデルでは、ソルバー評価ではなく、スループットと相対的パフォーマンスの類似の比較基準である反復/分が出力されます。これらのテストにおける正確な反復/分の出力は以下のとおりです。

この難易度の非常に高いモデルに関しても、4 つの Azure HPC VM のいずれも、最大の計測スケールとなる 128 台の VM まで効率的にスケーリングします。これは、HPC 中心のプロセッサの選択、低ジッターのハイパーバイザー、および Azure での 100 Gb EDR (HC シリーズ VM) と 20 Gb HDR 200 ネットワーク (HBv3 および HBv2 シリーズ VM) の使用の組み合わせによるものです。
- Milan-X を搭載した HBv3: 106% のスケーリング効率
- Milan を搭載した HBv3: 97% のスケーリング効率
- Rome を搭載した HBv2: 98% のスケーリング効率
- Skylake を搭載した HC: 96% のスケーリング効率
CPU ごとの比較において、VM が 128 台のときに相対的差異が最大となっており、Milan-X が Milan と比べて 16%、Rome と比べて 20%、Skylake と比べて 131% 高いパフォーマンスを示しています。
OpenFOAM v. 1912
よく知られている Motorbike ベンチマークの 2,800 万セル バージョンを実施しました。これは、今年、Azure HBv2 VM での OpenFOAM のパフォーマンスとコストの最適化で Azure HBv2 シリーズ VM でのパフォーマンスを紹介した OpenFOAM と同じモデルおよびバージョンです。
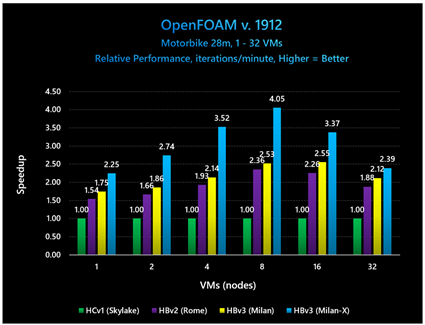
図 7: 中規模の OpenFOAM モデルにおいて、Milan-X は VM が 8 台のときに最大のパフォーマンス向上を示している
これらのテストにおける正確な反復/分の出力は以下のとおりです。
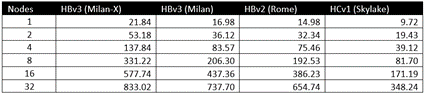
この難易度の高いモデルに関して、4 つの Azure HPC VM のいずれも、最大の計測スケールとなる 32 台の VM まで効率的にスケーリングします。
- Milan-X を搭載した HBv3: 119% のスケーリング効率
- Milan を搭載した HBv3: 135% のスケーリング効率
- Rome を搭載した HBv2: 137% のスケーリング効率
- Skylake を搭載した HC: 112% のスケーリング効率
とは言え、このサイズの問題において、VM が 8 台のときにスケーリング効率が最大になることは明らかです。Milan-X のスケーリング効率が際立っています。
- Milan-X を搭載した HBv3: 190% のスケーリング効率
- Milan を搭載した HBv3: 152% のスケーリング効率
- Rome を搭載した HBv2: 161% のスケーリング効率
- Skylake を搭載した HC: 105% のスケーリング効率
CPU ごとの比較において、VM が 8 台のときに相対的差異が最大となっており、Milan-X が Milan と比べて 60%、Rome と比べて 72%、Skylake と比べて 305% 高いパフォーマンスを示しています。
Siemens Simcenter Star-CCM+ v. 16.04.002
レーシング カーの外気流をシミュレーションする Le Mans Coupled モデルの 1 億セル バージョンを実行しました。これは、288 台の VM (33,408 CPU コア、PPN=116) までのスケーリングを含む、2021 年 3 月の一般提供開始時の HBv3 シリーズのベンチマーク に使用したのと同じモデルです。

図 8: 大規模な Simcenter Star-CCM+ モデルにおいて、Milan-X は VM が 64 台のときに最大のパフォーマンス向上を示している
これらのテストにおける正確な解決時間 (平均経過時間) の出力は以下のとおりです。
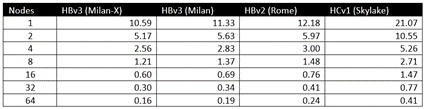
この難易度の高いモデルに関して、4 つの Azure HPC VM のいずれも、最大の計測スケールとなる 64 台の VM まで効率的にスケーリングします。
- Milan-X を搭載した HBv3: 103% のスケーリング効率
- Milan を搭載した HBv3: 93% のスケーリング効率
- Rome を搭載した HBv2: 79% のスケーリング効率
- Skylake を搭載した HC: 80% のスケーリング効率
CPU ごとの比較において、VM が 64 台のときに相対的差異が最大となっており、Milan-X が Milan と比べて 19%、Rome と比べて 50%、Skylake と比べて 156% 高いパフォーマンスを示しています。
WRF v. 4.1.5
[注: WRF では、結果は一般的に “シミュレーション速度” で示され、値が高い方が良い結果となります]
よく知られている気象シミュレーション アプリケーション WRF v. 4.1.5 で conus 2.5km モデルを実行しました。
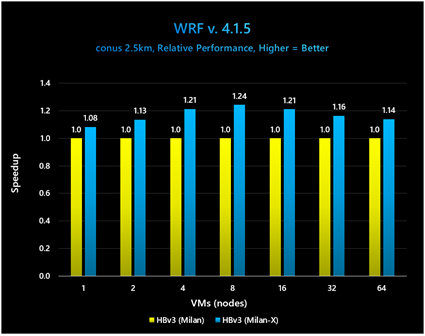
図 9: conus 2.5km ベンチマークにおいて、Milan-X は VM が 8 台のときに最大のパフォーマンス向上を示している
正確なシミュレーション速度の出力は以下のとおりです。
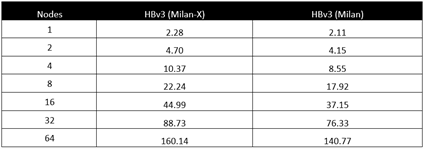
conus 2.5km ベンチマークに関して、Milan-X も Milan も、最大の計測スケールとなる 64 台の VM まで効率的にスケーリングします。
- Milan-X を搭載した HBv3: 110% のスケーリング効率
- Milan を搭載した HBv3: 104% のスケーリング効率
CPU ごとの比較において、VM が 8 台のときに相対的差異が最大となっており、Milan-X が Milan と比べて 24% 高いパフォーマンスを示しています。
NAMD v. 2.15
[注: NAMD では、結果は一般的に “シミュレーションされたナノ秒/日” で示され、値が高い方が良い結果となります]
イリノイ大学アーバナ シャンペーン校の Theoretical and Computational Biophysics Group 開発のよく知られた分子動力学シミュレーター NAMD を実行しました。

図 10: このコンピューティングの制約を受けるワークロードにおいて、Milan-X は最小のパフォーマンス向上を示している
正確なナノ秒/日の出力は以下のとおりです。
このコンピューティングの制約を受けるワークロード (メモリ パフォーマンスの制約を受けるワークロードではない) において、初めて、Milan-X で大幅なパフォーマンス向上が見られませんでした (2 ~3% のみ)。これは、この記事の冒頭で紹介した、ワークロードがそもそもメモリ パフォーマンスによる制約を受けるものでなければ、Milan-X が Milan を大幅に上回るパフォーマンスを実現しないという原則を明確に示しています。
HPC ワークロードのコスト/パフォーマンスへの影響
上記のデータは、Milan-X が極めて高いスケーリング効率を実現することを示しています。これらのワークロードや同様のモデルを HBv3 シリーズ VM で大規模に実行することで、Azure のお客様の投資利益率に大きな影響を及ぼすことができます。つまり、スケーリング効率 (コンピューティング ユニットを増やすごとに短縮される解決時間の割合) と Azure VM のコスト (VM の課金時間 x 使用している VM の数) との間には明確な関連性があります。
- ほぼ線形のスケーリング効率とは、VM が 1 台 (または問題を実行するのに必要な VM の最小数) のときよりもわずかに高い VM コストでパフォーマンスが向上することを意味します。
- 線形のスケーリング効率 (HPC における絶対的基準) とは、VM が 1 台 (または問題を実行するのに必要な VM の最小数) のときと同じ VM コストでパフォーマンスが向上することを意味します。
- 超線形のスケーリング効率とは、VM が 1 台 (または問題を実行するために必要な VM の最小数) のときよりも低い総 VM コストでパフォーマンスが向上することを意味します。
大半のパブリック クラウドや、さらには多くのオンプレミス HPC クラスターでも、ほぼ線形のスケーリング効率が妥当な目標と見なされています。一方、Azure がたびたび示してきたように、マイクロソフトの既存の HPC VM は、多くの場合において、線形のパフォーマンス向上を既に実現できています。一定の VM コストで非常に大規模なパフォーマンス向上を実現できるため、お客様にとってこれはおおいに価値があります。
ただし、上記のデータは、既にスケーラビリティの高い Azure HBv3 シリーズ VM を Milan-X プロセッサと組み合わせることで、解決時間の大幅な短縮と VM コストの削減の両方を実現できることを示しています。
以下の表は、f1_racecar_140m セル モデルでの Ansys Fluent のパフォーマンス情報を使用して、64 台の VM (7,680 CPU コア) までパフォーマンスが向上していくのに応じて、Azure のコンピューティング コストがどのように減少していくか示しています。
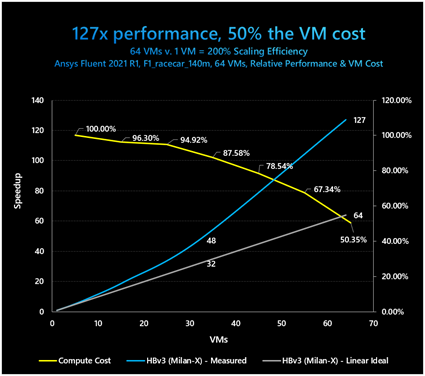
図 11: 64 台 の VM まで 200% のスケーリング効率を示す Milan-X を搭載した HBv3 シリーズ VM
このモデルでは、強力なスケーリングにより、アクティブなデータセットの十分な割合をメモリ内に収めることが段階的に可能になっていきます。それに応じて、メモリ帯域幅の増幅も大きくなるため、スケーリング効率が段階的に高くなっていき、最終的に 200% まで高くなります。
つまり、Milan-X を搭載した HBv3 VM を 64 台使用した場合、VM が 1 台のときのわずか半分の時間でこのシミュレーションを完了できます。これにより、VM コストを 50% 削減でき、解決時間を 127 分の 1 に短縮できます。