
소개
Advitya Gemawat currently leads LLM fine-tuning efforts to accelerate merge conflict resolution in the planet’s largest git codebase (the Windows OS repo), and is building Agents to accelerate Windows’ monthly Software Updates.
He started at Microsoft as part of the 4th cohort of the Microsoft AI Development Acceleration Program (MAIDAP) (opens in new tab) (working with Azure Quality, Microsoft’s Gray Systems Lab (GSL), Azure Edge & Platform, and Azure Machine Learning (AML)), and subsequently worked on RAI tooling for CV models and shipped Azure OpenAI Evaluation on Microsoft Foundry, in the Azure AI Platform org.
His research experience is at the intersection of Machine Learning & Scalable Systems. His work with GSL was identified as the Microsoft Global Hackathon Executive Challenge 2022 Winner (opens in new tab) and recipient of the Best Demonstration Award (opens in new tab) at VLDB 2022. His work with AML on expanding the RAI Dashboard to support Object Detection models was released in Public Preview at Microsoft Build 2023 (opens in new tab).
Prior to Microsoft, Advitya graduated from UC San Diego with a Data Science major, where he contributed to Project Cerebro (opens in new tab) (a Layered Data Platform for scalable Deep Learning) and was advised by Professor Arun Kumar (opens in new tab). There, his research won the 2021 ACM SIGMOD Student Research Abstract Competition and the Best Project Award as part of UCSD’s HDSI Scholarship Program. As part of his internship with VMware, his work on Massively Parallel Automated Model Building for Deep Learning (opens in new tab) was included in Apache MADlib (opens in new tab)‘s 1.18.0 release.
Featured Links
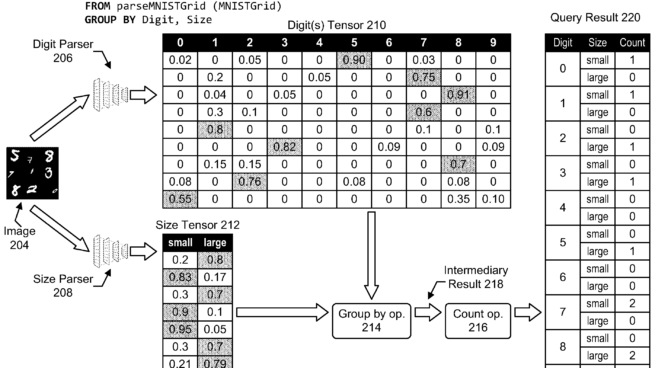
Patent | Method and system for extending query processing with differentiable operators
Example aspects include techniques for query processing over deep neural network runtimes. These techniques include receiving a query including a query operator and a trainable user defined function (UDF). In addition, the techniques include determining a query representation based on the query, and determining, for performing the query in a neural network runtime, an initial neural network program based on the query representation, the initial neural network program including a differentiable operators corresponding to the query operator. and executing the neural network program in the neural network runtime over the neural network data structure to generate a query result. Further, the techniques include training the initial neural network program via the neural network runtime to determine a trained neural network program, and executing the trained neural network program in the neural network runtime to generate inference information.
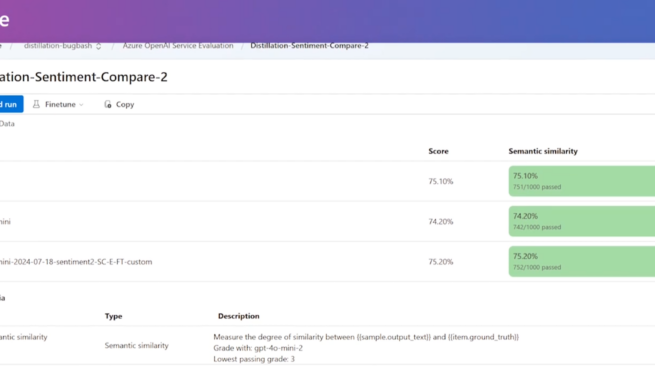
Enhancing Efficiency and Performance for Fine-Tuning with Distillation in Azure OpenAI Service
Implemented and shipped Azure OpenAI Evaluation (as part of the Azure OpenAI Model Distillation story), announced at Microsoft Ignite 2024, Microsoft Build 2025, and released in Public Preview.