

Physical AI research
Developing intelligent systems that perform complex tasks through understanding and engaging with physical environments
News & features
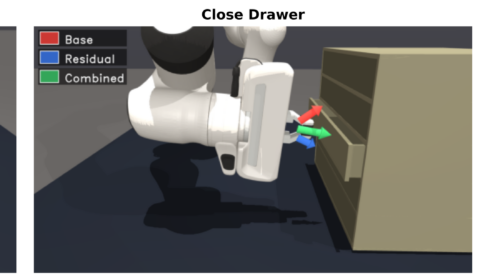
By Kinam Kim, Namiko Saito, Heecheol Kim, Katsushi Ikeuchi, Jaegul Choo and Yasuyuki Matsushita Vision-Language-Action (VLA) models enable broad manipulation capabilities by leveraging large-scale pretraining and robot demonstrations. However, imitation learning can cause small execution errors to accumulate over time, pushing…

Magma: A foundation model for multimodal AI agents across digital and physical worlds
| Swadheen Shukla, Jianwei Yang, Reuben Tan, Qianhui Wu, and Jianfeng Gao
Explore Magma, a foundation model that can empower AI assistants to interpret environments, plan actions, and execute tasks across digital and physical spaces. Now available, learn how it advances the field of agentic AI.

Introducing Muse: Our first generative AI model designed for gameplay ideation
| Katja Hofmann
Today Nature published Microsoft’s research detailing our WHAM, an AI model that generates video game visuals & controller actions. We are releasing the model weights, sample data, & WHAM Demonstrator on Azure AI Foundry, enabling researchers to build on the…
With the rapid advancements in AI and robotics, the development of highly intelligent robots capable of seamlessly interacting with the physical environment is becoming increasingly achievable. As the next AI wave, embodied AI innovations promise to revolutionize various industries and…